MapReduce基础案例11-倒排索引_2
什么是倒排索引?
倒排索引(Inverted index),也常被称为反向索引,是一种索引方法。
“倒排索引”是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。 它主要是用来存储某个单词(或词组)在一个文档或一组文档中的存储位置的映射,即提供了一种根据内容来查找文档的方式。 由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而称为倒排索引(Inverted Index)
通常情况下,倒排索引由一个单词(或词组)以及相关的文档列表组成,文档列表中的文档或者是标识文档的ID号,或者是指文档所在位置的URL,如下图所示(倒排索引结构):
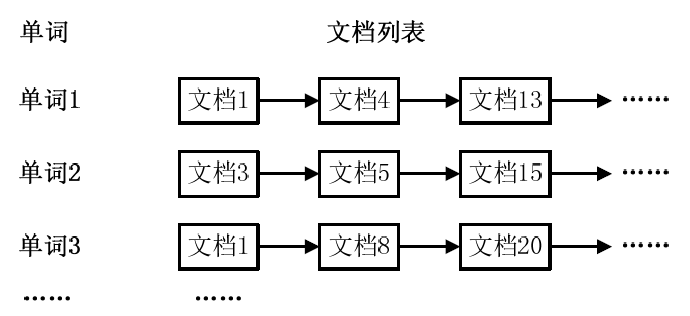
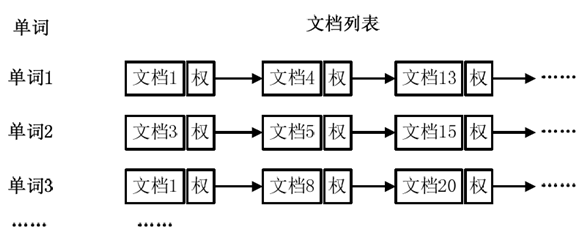
从上图中可以看出,单词1出现在{文档1,文档4,文档13,……}中,单词2出现在{文档3,文档5,文档15,……}中,而单词3出现在{文档1,文档8,文档20,……}中。在实际应用中,还需要给每个文档添加一个权值,用来指出每个文档与搜索内容的相关度,如下图所示(添加权重的倒排索引)。
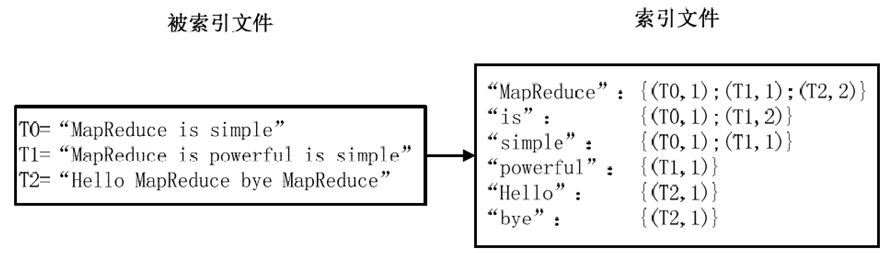
最常用的是使用词频作为权重,即记录单词在文档中出现的次数。以英文为例,如下图所示,索引文件中的"MapReduce"一行表示:"MapReduce"这个单词在文本T0中出现过1次,T1中出现过1次,T2中出现过2次。当搜索条件为"MapReduce"、"is"、"Simple"时,对应的集合为:{T0,T1,T2}∩{T0,T1}∩{T0,T1}={T0,T1},即文档T0和T1包含了所要索引的单词,而且只有T0是连续的。
更复杂的权重还可能要记录单词在多少个文档中出现过,以实现TF-IDF(Term Frequency-Inverse Document Frequency)算法,或者考虑单词在文档中的位置信息(单词是否出现在标题中,反映了单词在文档中的重要性)等。
问题描述
假设有三个文件file1.txt、file2.txt和file3.txt。三个文件内容如下所示。
file1.txt:
MapReduce is simple
file2.txt:
MapReduce is powerful is simple
file3.txt:
Hello MapReduce bye MapReduce
现希望统计每个单词在哪些文档中被引用过,引用了多少次。样例输出如下所示。
MapReduce file1.txt:1;file2.txt:1;file3.txt:2; is file1.txt:1;file2.txt:2; simple file1.txt:1;file2.txt:1; powerful file2.txt:1; Hello file3.txt:1; bye file3.txt:1;
实现思路
实现"倒排索引"只要关注的信息为:单词、文档URL及词频,如图3所示。但是在实现过程中,索引文件的格式与图3中会略有所不同,以避免重写OutPutFormat类。下面根据MapReduce的处理过程给出倒排索引的设计思路。
1)Map过程
首先使用默认的TextInputFormat类对输入文件进行处理,得到文本中每行的偏移量及其内容。显然,Map过程首先必须分析输入的
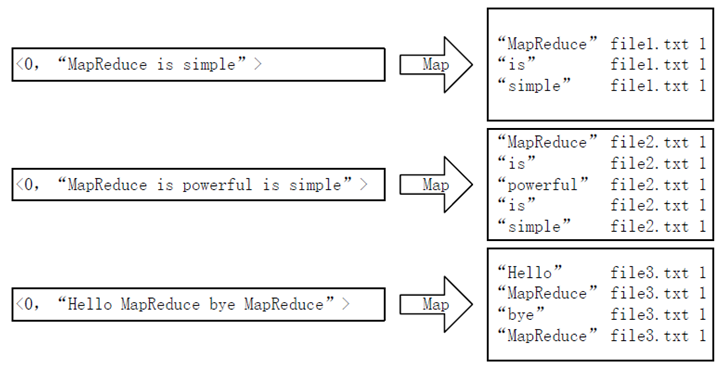
这里存在两个问题:
- 第一,
对只能有两个值,在不使用Hadoop自定义数据类型的情况下,需要根据情况将其中两个值合并成一个值,作为key或value值; - 第二,通过一个Reduce过程无法同时完成词频统计和生成文档列表,所以必须增加一个Combine过程完成词频统计。
这里讲单词和URL组成key值(如"MapReduce:file1.txt"),将词频作为value,这样做的好处是可以利用MapReduce框架自带的Map端排序,将同一文档的相同单词的词频组成列表,传递给Combine过程,实现类似于WordCount的功能。
2)Combine过程
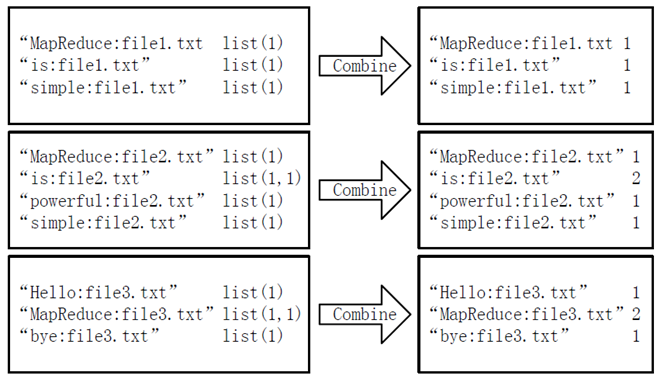
经过map方法处理后,Combine过程将key值相同的value值累加,得到一个单词在文档在文档中的词频,如下图所示。如果直接将下图所示的输出作为Reduce过程的输入,在Shuffle过程时将面临一个问题:所有具有相同单词的记录(由单词、URL和词频组成)应该交由同一个Reducer处理,但当前的key值无法保证这一点,所以必须修改key值和value值。这次将单词作为key值,URL和词频组成value值(如"file1.txt:1")。这样做的好处是可以利用MapReduce框架默认的HashPartitioner类完成Shuffle过程,将相同单词的所有记录发送给同一个Reducer进行处理。(Combine过程输入/输出)
3)Reduce过程
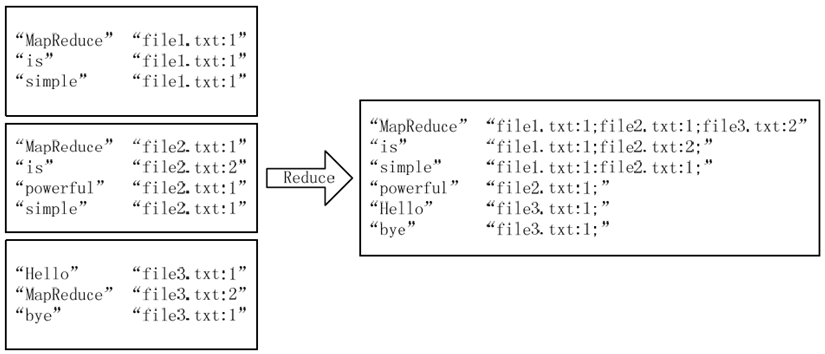
经过上述两个过程后,Reduce过程只需将相同key值的value值组合成倒排索引文件所需的格式即可,剩下的事情就可以直接交给MapReduce框架进行处理了。如下图所示。索引文件的内容除分隔符外与第1张图解释相同。
4)需要解决的问题
本实例设计的倒排索引在文件数目上没有限制,但是单词文件不宜过大(具体值与默认HDFS块大小及相关配置有关),要保证每个文件对应一个split。否则,由于Reduce过程没有进一步统计词频,最终结果可能会出现词频未统计完全的单词。可以通过重写InputFormat类将每个文件为一个split,避免上述情况。或者执行两次MapReduce,第一次MapReduce用于统计词频,第二次MapReduce用于生成倒排索引。除此之外,还可以利用复合键值对等实现包含更多信息的倒排索引。(Reduce过程输入/输出)
一、创建Java Maven项目
Maven依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>HadoopDemo</groupId>
<artifactId>com.xueai8</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!--hadoop依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<!--hdfs文件系统依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
<!--MapReduce相关的依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.3.1</version>
</dependency>
<!--junit依赖-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!--编译器插件用于编译拓扑-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<!--指定maven编译的jdk版本和字符集,如果不指定,maven3默认用jdk 1.5 maven2默认用jdk1.3-->
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source> <!-- 源代码使用的JDK版本 -->
<target>1.8</target> <!-- 需要生成的目标class文件的编译版本 -->
<encoding>UTF-8</encoding><!-- 字符集编码 -->
</configuration>
</plugin>
</plugins>
</build>
</project>
InvertedMapper.java:
package com.xueai8.invertedindex;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
/**
*
* 倒排索引 - 文档
*/
public class InvertedMapper extends Mapper<Object, Text, Text, Text> {
private Text keyInfo = new Text(); // 存储单词和URL组合 (MapReduce:file1.txt)
private Text valueInfo = new Text(); // 存储词频 (2)
private FileSplit split; // 存储Split对象
@Override
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
// 获得当前mapper所处理split的FileSplit对象
split = (FileSplit) context.getInputSplit();
// 这里为了好看,只获取文件的名称
String fileName = split.getPath().getName();
// 对一行文本进行分词
StringTokenizer itr = new StringTokenizer(value.toString());
// 将输入的数据首先按行进行分割
while (itr.hasMoreTokens()) {
// key值由单词和URL组成,如"MapReduce:file1.txt"
keyInfo.set(itr.nextToken() + ":" + fileName);
// 词频初始化为1
valueInfo.set("1");
// 写出<单词1:file1.txt, 1>
context.write(keyInfo, valueInfo);
}
}
}
InvertedCombiner.java
package com.xueai8.invertedindex;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
*
* 倒排索引 - 文档
*/
// 对同一个 [单词:文件名] 进行词频合并,然后重新组合 key-value对为 <单词,[文件名:词频,]>
public class InvertedCombiner extends Reducer<Text, Text, Text, Text> {
private Text keyInfo = new Text();
private Text valueInfo = new Text();
// 输入 <"MapReduce:file1.txt", [1,1,1,...]>
@Override
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// 统计词频
int sum = 0;
for (Text value : values) {
sum += Integer.parseInt(value.toString());
}
// 对"MapReduce:file1.txt"进行分词
String[] words = key.toString().split(":");
keyInfo.set(words[0]); // 重新设置key值为单词
valueInfo.set(words[1] + ":" + sum); // 重新设置value值由[URL:词频]组成
// 写出
context.write(keyInfo, valueInfo); // <单词,[文件名:词频]>
}
}
InvertedReducer.java
package com.xueai8.invertedindex;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
*
* 倒排索引 - 文档
*/
// 收到的为: <单词,[文件名1:词频1,文件名2:词频2,...]>
public class InvertedReducer extends Reducer<Text, Text, Text, Text> {
// 定义可重用的值对象
private Text result = new Text();
@Override
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// 生成文档列表
StringBuilder builder = new StringBuilder();
for (Text value : values) {
builder.append(value.toString());
builder.append(";");
}
result.set(builder.toString());
context.write(key, result);
}
}
InvertedDriver.java:
package com.xueai8.invertedindex;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
*
* 倒排索引 - 文档
*/
public class InvertedDriver {
public static void main(String[] args) throws Exception {
if (args.length < 2) {
System.err.println("语法: Inverted Index <in> <out>");
System.exit(1);// 非正常退出
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Inverted Index");
job.setJarByClass(InvertedDriver.class);
// 设置Map、Combine和Reduce处理类
job.setMapperClass(InvertedMapper.class);
job.setCombinerClass(InvertedCombiner.class);
job.setReducerClass(InvertedReducer.class);
// 设置map端的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入输出路径
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 提交作业并等待作业执行结束
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
二、配置log4j
在src/main/resources目录下新增log4j的配置文件log4j.properties,内容如下:
log4j.rootLogger = info,stdout
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
三、项目打包
打开IDEA下方的终端窗口terminal,执行"mvn clean package"打包命令,如下图所示:
如果一切正常,会提示打jar包成功。如下图所示:
这时查看项目结构,会看到多了一个target目录,打好的jar包就位于此目录下。如下图所示:
四、项目部署
请按以下步骤执行。
1、启动HDFS集群和YARN集群。在Linux终端窗口中,执行如下的脚本:
$ start-dfs.sh
$ start-yarn.sh
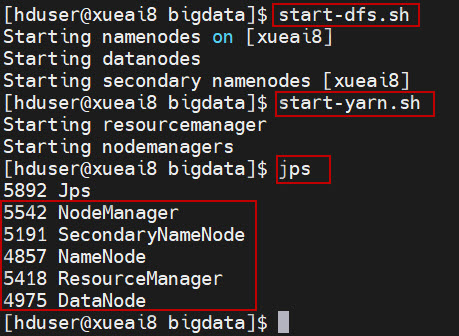
查看进程是否启动,集群运行是否正常。在Linux终端窗口中,执行如下的命令:
$ jps
这时应该能看到有如下5个进程正在运行,说明集群运行正常:
5542 NodeManager
5191 SecondaryNameNode
4857 NameNode
5418 ResourceManager
4975 DataNode
2、将数据文件sample.txt上传到HDFS的/data/mr/目录下。
$ hdfs dfs -mkdir -p /data/mr $ hdfs dfs -put input1.txt /data/mr/ $ hdfs dfs -put input2.txt /data/mr/ $ hdfs dfs -put input3.txt /data/mr/ $ hdfs dfs -ls /data/mr/
3、提交作业到Hadoop集群上运行。(如果jar包在Windows下,请先拷贝到Linux中。)
在终端窗口中,执行如下的作业提交命令:
$ hadoop jar com.xueai8-1.0-SNAPSHOT.jar com.xueai8.invertedindex.InvertedDriver /data/mr /data/mr-output
4、查看输出结果。
在终端窗口中,执行如下的HDFS命令,查看输出结果:
$ hdfs dfs -ls /data/mr-output
可以看到如下的输出结果:
Hello input3.txt:1; MapReduce input3.txt:2;input1.txt:1;input2.txt:1; bye input3.txt:1; is input1.txt:1;input2.txt:2; powerful input2.txt:1; simple input2.txt:1;input1.txt:1;
