机器学习概述
机器学习源自人工智能,它不是数据科学的分支。数据科学只是使用机器学习作为工具。统计和数学是机器学习算法的基础。
什么是机器学习?
机器学习是实现人工智能的一种重要方法,是人工智能领域的一个子领域。人工智能、机器学习(ML)和深度学习(DL)之间的关系如下图:
在数据科学领域,机器学习是一种数据分析方法,它可以自动建立分析模型。
机器学习是一种能够赋予机器学习的能力以此让它完成直接编程无法完成的功能的方法。 但从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。
一种经常引用的英文定义是:"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E"。机器学习强调三个关键词:算法、经验、性能,其处理过程如下图所示。
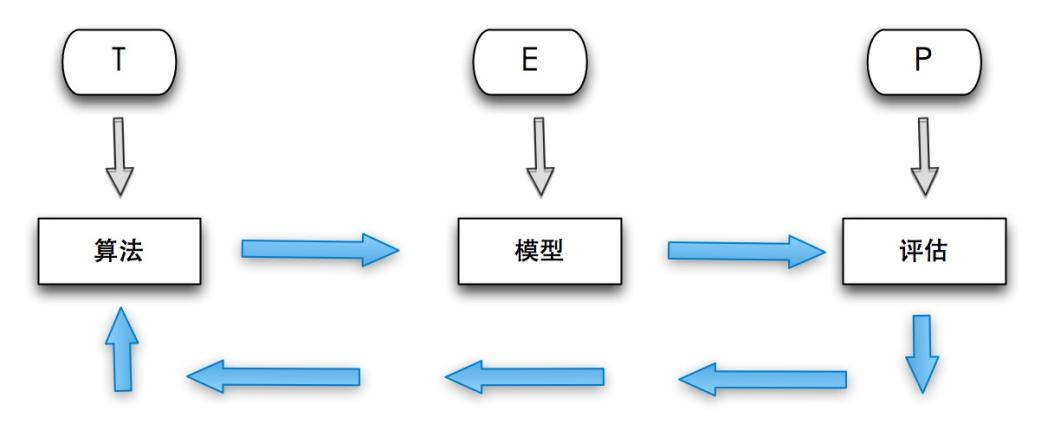
在数据的基础上,通过算法构建出模型并对模型进行评估。评估的性能如果达到要求,就用该模型来测试其他的数据;如果达不到要求,就要调整算法来重新建立模型,再次进行评估。如此循环往复,最终获得满意的经验来处理其他的数据。
可以说,机器学习的本质就是“重现人认识世界的过程”。机器学习就是通过实例数据学习。对于给定的输入,产生一个特定的输出。这个过程如下图所示:
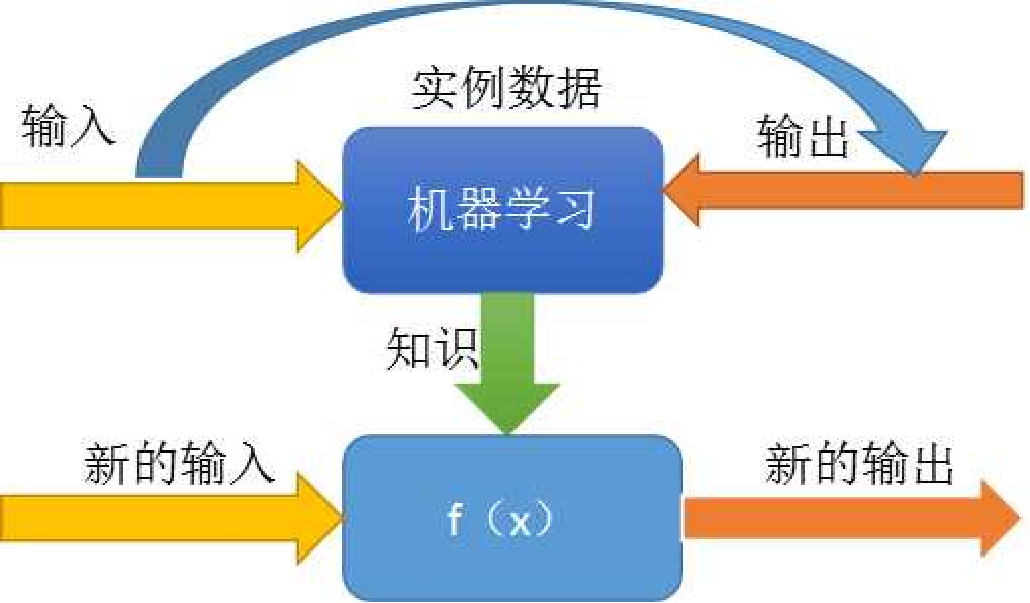
机器学习技术和方法已经被成功应用到多个领域,比如数据挖掘、个性化推荐系统、计算机视觉、自然语言处理和机器翻译、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、模式识别、智能控制、战略游戏和机器人等领域。
机器学习算法分类
机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。
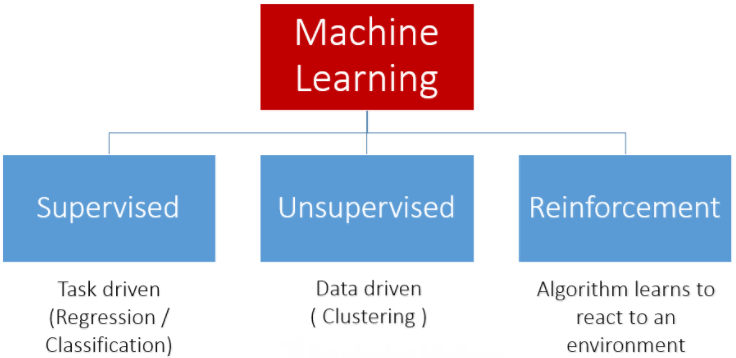
机器学习算法通常被分为三类:
- Supervised Learning(监督型学习):监督算法可以用于预测、估计、分类和其他类似的需求。
- Unsupervised Learning(无监督学习):这样的算法可以从数据学习关系和结构。使用无监督学习技术的例子有聚类和关联规则学习。
- Reinforcement learning(增强型学习):与前两种类型的学习不同,这一种学习不会从数据中学习。相反,它通过一系列的操作来学习与环境的交互,而反馈循环提供了它用来进行调整的信息。换句话说,它从自己的经验中学习。
如下图所示:
Supervised Learning(监督型学习)
监督学习被普遍应用于用历史数据预测未来可能发生的事件。
例如,预测什么时候信用卡交易可能是欺诈性的,或哪个保险客户可能提出索赔,预测股票价格,预测机器设备在出故障前的时间等。监督学习的一些应用还包括语音识别、信用评分、医学成像和搜索引擎。
在监督学习中,训练数据集中的每个示例都标记了算法应该自己给出的答案,这意味着在训练算法时拥有完整的标记数据集。例如,一个标记的花卉图像数据集将告诉模型哪些照片是玫瑰,雏菊和水仙花。当显示新图像时,该模型将其与训练示例进行比较,以预测正确的标签。
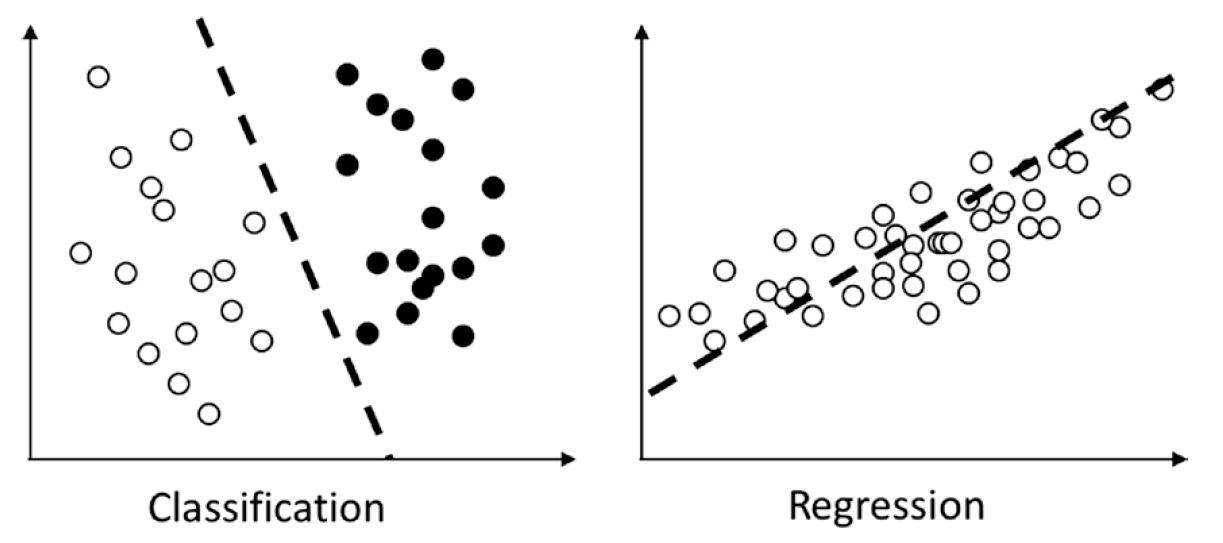
监督学习主要解决两种任务:分类任务和回归任务。
- 分类: 分类问题对构成输出的所有变量进行分类。分类问题要求算法预测离散值。例如,在动物图像集中,对每张照片分类它属于猫、考拉还是乌龟。
- 回归: 回归问题着眼于连续的数据。例如,在二手房网站,给定二手房的大小、房龄、面积、位置等信息,预估一个合适的二手销售价格。
分类和回归方法可以用下图来表示:
Unsupervised Learning(无监督学习)
在无监督学习过程中,系统没有具体的数据集,大多数问题的结果在很大程度上是未知的。用简单的术语来说,人工智能系统和ML目标在进入操作时是盲的。系统没有任何参考数据(即所谓的标签label)。无监督学习系统会识别所有相似的对象,并将它们分组。它给这些物体的标签将由机器自己设计。
无监督学习对事务性数据的处理效果很好。例如,信用卡欺诈检测,客户细分,图像分割,检测异常,分组搜索结果等。
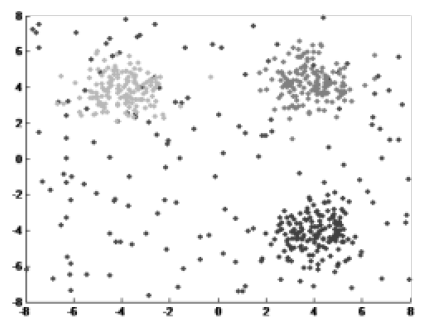
这种学习类型被设计用来解决不同的问题,即发现数据内隐藏的结构或模式。聚类和关联规则属于无监督学习类型。下图显示的就是聚类算法的原理:
监督型学习 Vs 无监督学习
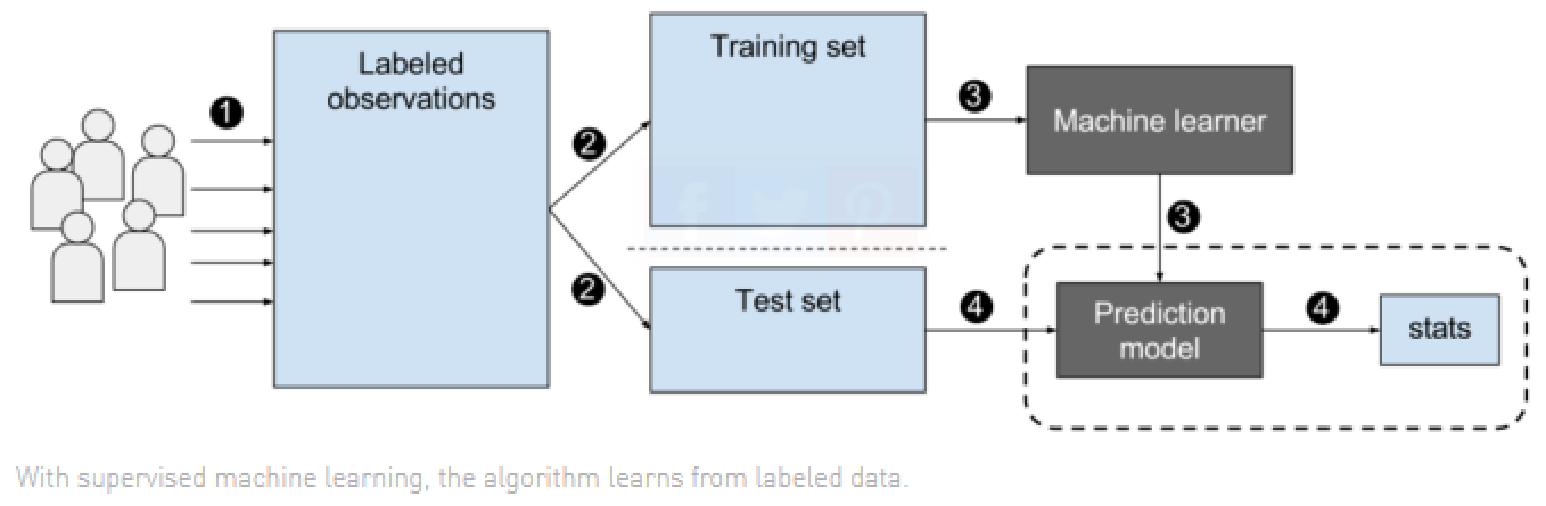
对于监督型学习,训练数据中的每一个观察对象都必须包含一个标签,无论它是离散的还是连续的。监督学习算法试图对目标预测输出和输入特征之间的关系和依赖关系建模,这样我们就可以根据从算法中学到的关系来预测新数据的输出值。其执行赛程如下图:
而无监督学习中用于训练机器学习算法的数据不包含标签,主要用于模式检测和描述建模。这些算法尝试对输入数据使用技术来挖掘规则、检测模式、总结和分组数据点,这些数据点有助于获得有意义的见解,并更好地向用户描述数据。无监督学习算法是机器学习算法的一个分支,主要用于模式检测和描述建模。
无监督学习的一些应用包括市场营销中的客户细分、社交网络分析、图像分割、气候学等等。

强化学习
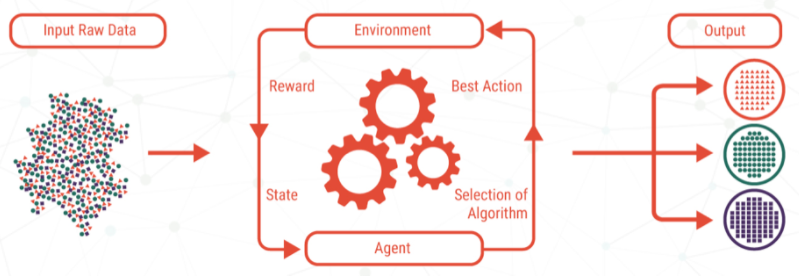
强化学习从无监督学习的概念出发,给软件代理和机器一个高度的控制范围,以确定在一个环境中什么是理想的行为。 这里需要简单的反馈来告知机器它的进度,以帮助机器学习它的行为。
强化学习并不简单,它需要大量不同的算法来解决。事实上,在强化学习中,agent根据结果的当前状态来决定最佳行为。如下图所示:
数据描述
为了能够与机器交流训练示例(训练数据点),必须以适当的方式描述它们。最常见的机制依赖于所谓的属性(attribute)。
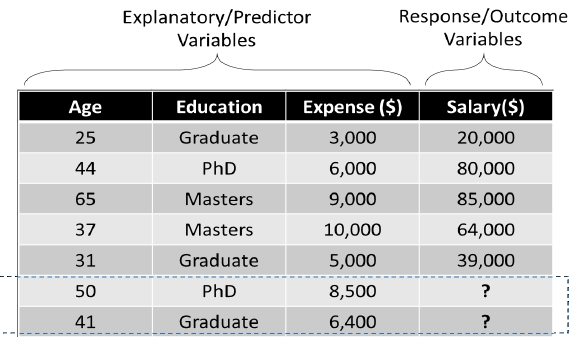
如下图,根据用户的年龄、受教育程序及花费,预测其收入。问:应该应用哪种机器学习方法?
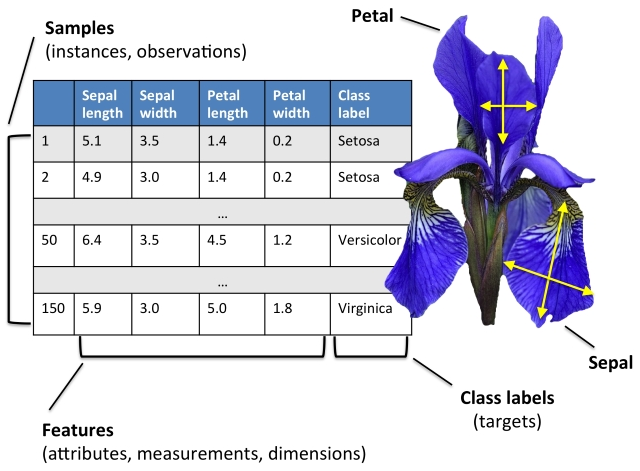
对于监督型学习算法,需要使用带有label(标签)的训练数据集。例如,下图展示了一个带标签label的鸢尾花数据集。每组数据在图中表示为一行,花朵的测量尺寸分别在列中表示(特征数据集,属性),最后一列class label即为标签列,也叫目标(target)列。通过花萼长度、花萼宽度、花瓣长度、花瓣宽度4个属性,预测鸢尾花卉属于(Setosa(山鸢尾),Versicolour(杂色鸢尾),Virginica(维吉尼亚鸢尾))三个种类中的哪一类,即预测目标列的值。
机器学习过程
为了有效地将机器学习应用于智能应用程序的开发,应该考虑采用一组大多数机器学习实践者所遵从的最佳实践。一般来说,机器学习任务包括以下步骤:
- (1) 读取数据。
- (2) 对数据进行预处理或准备。
- (3) 提取特征。
- (4) 为训练、验证和测试拆分数据。
- (5) 使用训练数据集训练模型。
- (6) 使用交叉验证技术优化模型。
- (7) 在测试数据集上评估模型。
- (8) 部署模型。
一个机器学习项目由多个步骤组成,每个步骤代表机器学习管道中的一个阶段。典型的步骤如下图所示:
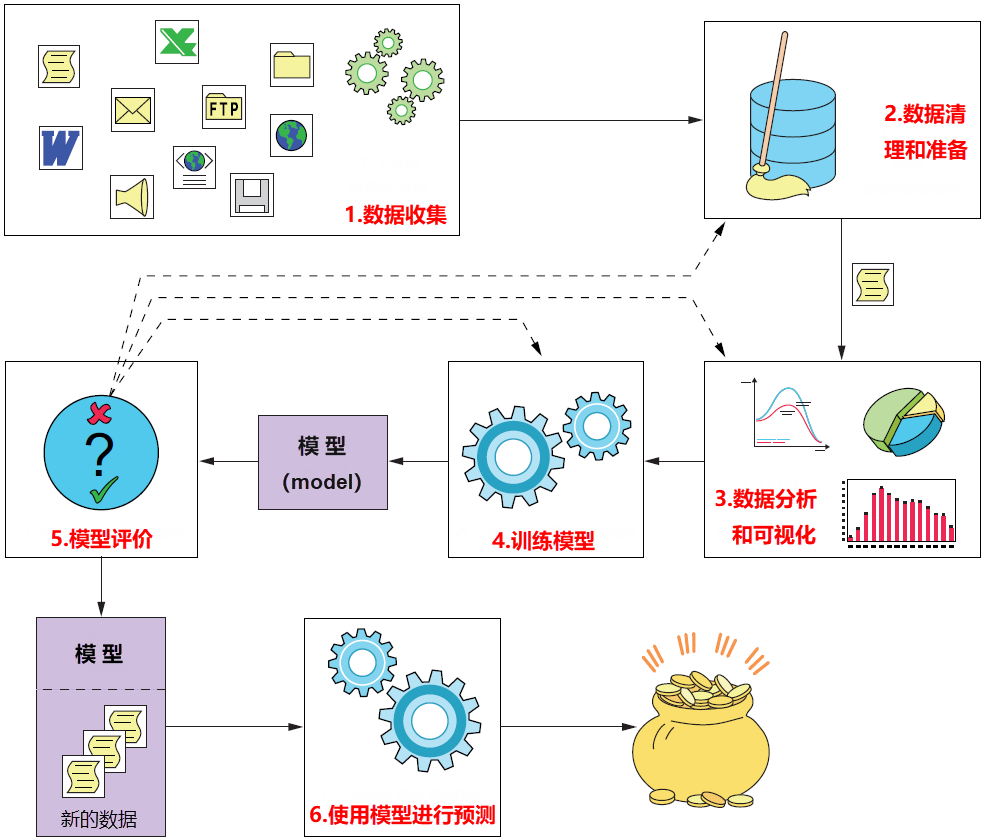
机器学习应用程序开发过程通常包括以下步骤:
(1) 数据摄取:典型的机器学习管道摄取的输入数据来自多个数据源,通常有着不同的数据格式。这些源可以包括文件、数据库(RDBMS、NoSQL、Graph等)、Web服务(例如REST端点)、Kafka和Amazon Kinesis流等。
(2) 数据清洗和预处理:数据清洗是整个数据分析管道中的关键步骤。通常包括过滤数据,处理丢失、不完整或损坏的数据,处理潜在的异常、错误和异常值,将不同的数据源连接在一起,聚合数据等。该预处理步骤修复了数据质量问题,使之适合机器学习模型使用。
(3) 特征工程:在这一步中,我们使用各种技术从输入数据中提取和生成特定的特征,然后将它们组合成一个特征向量,并传递到流程的下一个步骤。通常,使用VectorAssembler从指定的DataFrame列创建特征向量。大多数机器学习算法都是基于特征的,这些特征通常是用于模型的输入变量的数值表示。
(4) 模型训练:机器学习模型训练包括指定一个算法和一些训练数据(模型可以从中学习)。通常,我们将输入数据集分为训练数据集和测试数据集,为每个数据集随机选择一定比例的输入记录。模型通过在训练数据集上调用fit()方法进行训练。
(5) 模型验证:这一步包括评估和优化ML模型,以评估预测的好坏。在此步骤中,使用transform()方法将模型应用于测试数据集,并计算模型的合适的性能度量,例如精度、错误等。
(6) 模型选择:在此步骤中,我们不断尝试和调整Transformer和Estimator的超参数,以生成最优的ML模型。通常,我们创建一个参数网格,并使用称为交叉验证的过程对给定模型最合适的参数集执行网格搜索。交叉验证器返回的最佳模型可以保存并稍后加载到生产环境中。
(7) 模型部署:最后,我们部署用于生产的最优模型。部署的模型需要在生产环境中持续维护、升级、优化等等。
