PySpark架构
PySpark构建在Spark的Java API之上。数据在Python中处理,在JVM中缓存和Shuffle。PySpark架构如下图所示:
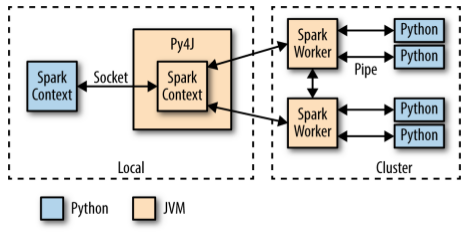
在Python驱动程序中,当PySpark的Python解释器启动时,SparkContext使用Py4J启动JVM并创建JavaSparkContext,并通过Socket套接字与之通信。JVM作为实际的Spark驱动程序运行,并通过JavaSparkContext与集群中的Spark Executor进行通信。Py4J只在驱动程序上用于Python和JavaSparkContext对象之间的本地通信(大型数据传输是通过一种不同的机制执行的)。
对SparkContext对象的Python API调用被转换为对JavaSparkContext的Java API调用。例如,PySpark的 sc.textFile()的实现分派为对JavaSparkContext的. textFile()方法的调用,该方法最终与Spark Executor JVM通信,以从HDFS加载文本数据。
集群上的Spark Executor为每个core启动一个Python解释器,当它们需要执行用户代码时,通过管道与该解释器通信,发送用户代码和要处理的数据。
本地PySpark客户端中的PythonRDD对应于本地JVM中的PythonRDD对象。与此RDD关联的数据实际上作为Java对象存在于Spark JVM中。例如,在Python解释器中运行sc.textFile()将调用JavaSparkContext的textFile()方法,该方法将数据作为Java字符串对象加载到集群中。类似地,使用newAPIHadoopFile加载Parquet/Avro文件将以Java Avro对象的形式加载对象。
PySpark目前使用Python cPickle序列化器序列化数据。PySpark使用cPickle序列化数据,因为它相当快,并且支持几乎任何Python数据结构。当在Python RDD上进行API调用时,任何相关的代码(例如Python lambda函数)都会通过“cloudpickle(一个由PiCloud构建的定制模块)”进行序列化,并分发给执行器。然后将数据从Java对象转换为与Python兼容的表示(例如pickle对象),并通过管道流向与executor相关的Python解释器。
任何必要的Python处理都在解释器中执行,结果数据作为RDD(默认情况下作为pickle对象)存储回JVM中。
