HBase的安装和部署(3)_完全分布模式
说明:平台基于CentOS 7.x操作系统。用户名及软件安装目录如下:
| 环境 | 设置或路径 |
|---|---|
| 用户名 | hduser |
| 用户主目录 | /home/hduser |
| 软件安装包位于 | /home/hduser/software |
| 软件安装位置 | /home/hduser/bigdata/ |
HBase具有多种部署模式。
- 独立模式:使用本地文件系统作为存储,它在同一个JVM中运行所有HBase守护进程和本地ZooKeeper。
- 伪分布模式:使用HDFS系统或者本地作为存储,守护进程都在单个节点上运行。
- 完全分布式:只能使用HDFS存储系统,HBase守护程序的多个实例在群集中的多个服务器上运行。
接下来我们学习HBase完全分布模式安装,使用三个节点构成的集群,三个节点的机器名分别为:master、worker01和worker02。
对于生产环境,建议使用完全分布式HBase集群。在完全分布式模式下,HBase守护程序的多个实例在群集中的多个服务器上运行。
一、预备操作
1、设置CentOS最大进程数和最大文件打开数(修改ulimit和nproc)
查看操作系统可以打开最大文件描述符的数量(默认是1024):
$ ulimit -n
查看操作系统允许用户最大可用的进程数量(默认是4096)。
$ ulimit -u
怎么在Linux中设置ulimit?
编辑/etc/security/limits.conf,这是一个以空格分隔的文件,有4列。设置内容如下:
hduser soft nofile 10240 hduser hard nofile 10240 hduser soft nproc 10240 hduser hard nproc 10240
其中:
- noproc: 是代表最大进程数
- nofile: 是代表最大文件打开数
2、设置NTP(三台都设)
使用NTP(Network Time Protocol)同步系统时钟和外部时间服务器。要求有root权限,保持连网。
$ sudo yum install ntp # 安装一个NTP Service $ sudo /sbin/chkconfig ntpd on # 开机启用
注:不同机器间的时间误差不得超过30秒。
3、HDFS DataNode对它将在任何时间服务的文件数量有一个上限。
打开Hadoop的conf/hdfs-site.xml文件,设置dfs.datanode.max.transfer.threads参数:
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>4096</value>
</property>
这个参数用来指定用于在DataNode内外传输数据的最大线程数。
完成上述配置后,请确保重新启动HDFS(如果已经启动了HDFS的话)。
二、安装HBase
请按以下步骤下载和安装HBase。
1、从以下地址下载HBase压缩包到本地文件系统:下载HBase安装包
注意,选择合适的版本。这里我们选择长期稳定版2.3.5(您下载时也许版本有所变化),如下图所示:
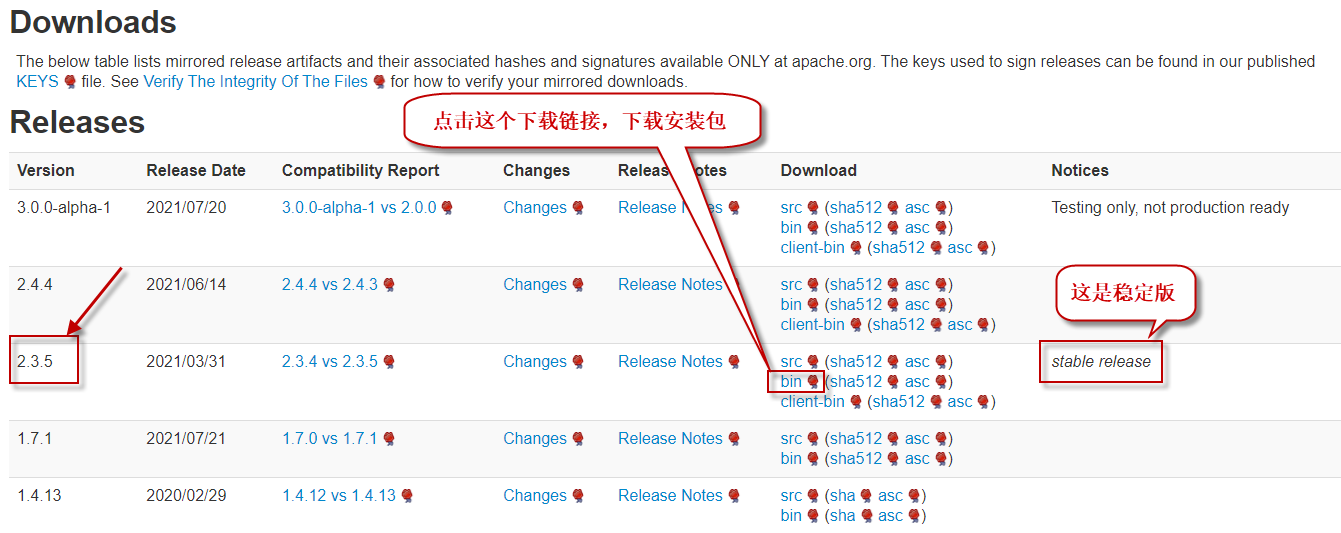
将下载的.tar.gz结尾的文件,放在/home/hduser/software/目录下。
2、解压缩下载的压缩包到用户主目录:
$ cd ~/bigdata $ tar -zxvf ~/software/hbase-2.3.5-bin.tar.gz
3、配置hbase环境变量(三个节点都做):
$ sudo nano /etc/profile
在文件的最后,加上如下内容:
export HBASE_HOME=/home/hduser/bigdata/hbase-2.3.5 export PATH=$PATH:$HBASE_HOME/bin
4、执行/etc/profile文件,使环境变量生效:
$ source /etc/profile
5、测试环境变量配置:
$ hbase version
出现hbase版本信息,就说明hbase环境变量配置正确。
三、配置HBase
配置$HBASE_HOME/conf/中的文件,包括:
- hbase-env.sh
- hbase-site.xml
- regionservers
1、打开$HBASE_HOME/conf/hbase-env.sh文件,将下面配置项前的注释取消,并修改JAVA_HOME变量值为你自己的jdk安装主目录:
export JAVA_HOME=/usr/local/jdk1.8.0_251 export HBASE_MANAGES_ZK=true
上面第二个配置项的含义是,使用HBase自带的Zookeeper。
2、打开$HBASE_HOME/conf/hbase-site.xml文件配置如下属性:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master:2181,worker01:2181,worker02:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hduser/bigdata/hbase-2.3.5/zoodata</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/hduser/bigdata/hbase-2.3.5/tmp</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
</configuration>
3、打开$HBASE_HOME/conf/regionservers:
它列出了所有运行HRegionServer守护进程的主机名。每行一个主机名(类似于Hadoop的slaves文件)。
在这个文件中列出的所有服务器在HBase集群启动或停止脚本运行时,都将被启动或停止。
默认该文件只包含localhost项。删除包含localhost的这一行,添加worker01和worker02的主机名或IP地址。
$ nano regionservers
在打开的文件中,填写每个节点的机器名或IP地址,一个节点一行:
master slave1 slave2
4、替换掉HBase绑定的Hadoop
因为HBase需要依赖Hadoop,它在其lib目录下绑定了Hadoop jar的一个实例。这个绑定的jar包仅用在独立(standalone)模式。在分布式模式下,严格要求集群上的Hadoop版本与HBase上的Hadoop版本保持一致。如果两者不一致,则需要使用Hadoop集群的hadoop jar包替换掉HBase lib目录下的hadoop jar包,以避免版本冲突问题。
首先,执行以下命令,删除掉 HBase 下的所有 Hadoop 相关的 jar 包:
$ rm -rf /home/hduser/bigdata/hbase-2.3.5/lib/hadoop*.jar
再执行以下命令,拷贝所有 Hadoop(例如,Hadoop 3.1.2 版本) 下的 jar 包到 HBase的lib目录下进行版本统一:
$ find /home/hduser/bigdata/hadoop-3.1.3/share/hadoop/ -name "hadoop*jar" | xargs -i cp {} /home/hduser/bigdata/hbase-2.3.5/lib/
5、从master拷贝配置好的hbase到节点worker01和worker02。
集群中的每个节点都需要有相同的配置信息。
$ cd $ scp -r ~/bigdata/hbase-2.3.5 hduser@worker01:~/bigdata/ $ scp -r ~/bigdata/hbase-2.3.5 hduser@worker02:~/bigdata/
四、启动和测试HBase
1、启动HDFS集群:
$ start-dfs.sh
2、启动HBase:
$ start-hbase.sh
3、查看进程:
$ jps
如果系统配置正确,jps命令应该显示HMaster和HRegionServer进程正在运行。
4、检查HDFS上的hbase数据目录。如果一切正常,HBase会创建该目录。
在上面的配置中,它存储在HDFS之上的/hbase/中。可以使用hadoop fs命令或hdfs dfs命令列出这个目录。
$ hdfs dfs -ls /hbase
5、浏览Web UI。
HBase Web UI所使用的HTTP端口,Master为16010,RegionServer为16030。
如果一切正确,可以使用web浏览器连接Master UI - http://localhost:16010
可以在每个RegionServers的IP地址和16030端口上查看用于每个RegionServers的Web UI。
6、停止HBase。使用如下命令:
$ stop-hbase.sh
