案例:运输公司车辆超速实时监测
假设有一个物流公司车队管理解决方案,其中车队中的车辆启用了无线网络功能。每辆运输车需要定期报告其地理位置和多个操作参数,如燃油水平、速度、加速度、轴承、发动机温度等。物流公司希望利用这一远程实时监测数据流来实现一系列应用程序,以帮助他们管理业务的运营和财务方面。
现在我们承担了其中一个任务,需要开发一个流应用程序,实时统计运输车辆每几秒钟的平均速度,用来检查车辆是否超速。程序整体架构如下图所示。

在本案例中,使用Kafka作为流数据源,将从Kafka的cars主题来读取这些事件。同时也将Kafka作为流的Data Sink,检测出的超速事件将写入到Kafka的fastcars主题。
1. 实现技术剖析
PySpark在处理实时数据流时,它会等待一个非常小的间隔,比如1秒(或者甚至0秒—即尽可能地快)。将在此间隔期间收到的所有事件合并到一个微批处理中。在结构化流中,微批数据被构造为一个流式的DataFrame(即无界表),如下图所示。
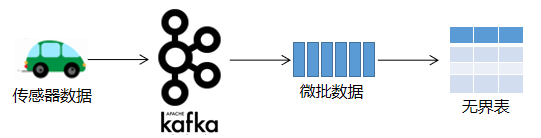
这个微批处理然后由驱动程序(Driver)调度,作为任务(Task)在执行器(Executor)中执行。完成微批处理执行后,将再次收集并调度下一批。这种调度是经常进行的,以给人以流执行的印象,如下图所示。
 会员登录
会员登录
