关于sortByKey和groupByKey
关于sortByKey
Pair RDD的sortByKey函数作用于Key-Value形式的RDD,并对Key进行排序。该函数返回的RDD一定是ShuffledRDD类型的,因为对源RDD进行排序,必须进行Shuffle操作,而Shuffle操作的结果RDD就是ShuffledRDD。
其实这个函数的实现很优雅,里面用到了RangePartitioner,它可以使得相应的范围key数据分到同一个partition中,然后内部用到了mapPartitions对每个partition中的数据进行排序,而每个partition中数据的排序用到了标准的sort机制,避免了大量数据的shuffle。
请看下面这个示例:
a = sc.parallelize(["xlw", "snail", "xueai8", "39657", "about"], 2) b = sc.parallelize(range(a.count()) , 2) c = a.zip(b) # 拉链操作 c.sortByKey().collect() # 按key排序
执行以上代码,输出结果如下:
[('39657', 3), ('about', 4), ('snail', 1), ('xlw', 0), ('xueai8', 2)]
关于groupByKey
Pair RDD的groupByKey函数以迭代器的形式收集每个key的值。顾名思义,groupByKey函数会把同一个key的所有值分到一组中。与reduceByKey不同的是,它不会对最终输出进行任何形式的操作,它只是对数据进行分组并以迭代器的形式返回。它是一个transformation转换操作,这意味着它的计算是惰性的。
假设,现在有这么一组数据:
data = [("USA", 1), ("USA", 2), ("India", 1),
("UK", 1), ("India", 4), ("India", 9),
("USA", 8), ("USA", 3), ("India", 4),
("UK", 6), ("UK", 9), ("UK", 5)]
将其构造为具有3个分区的一个RDD:
x = spark.sparkContext.parallelize(data, 3)
现在,因为在源RDD中,每个key都可以存在于任何分区中,所以当对这个RDD执行groupByKey转换时,它需要将同一个key的所有数据shuffle到单个分区(除非源RDD已经按key分区了)。这种shuffling使这种转换成为一种宽依赖的转换。如下图所示:
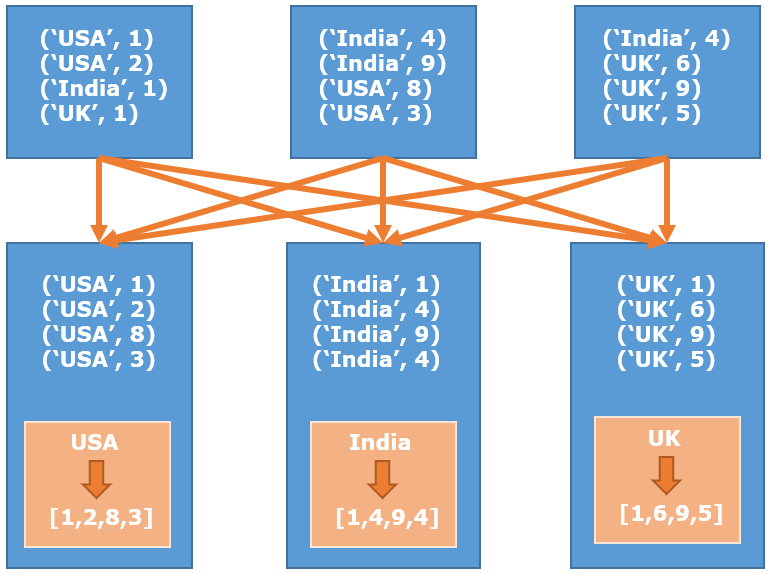
这个函数有三个变体:
- groupByKey():将RDD中每个key的值分组为单个序列。
- groupByKey(numPartition):参数用于指定结果RDD中的分区数。
- groupByKey(partitioner):使用partitioner在结果RDD中创建分区。
【示例】使用groupByKey函数对Pair RDD进行分组。
from pyspark.sql import SparkSession
# 构建SparkSession和SparkContext实例
spark = SparkSession.builder \
.master("spark://xueai8:7077") \
.appName("pyspark demo") \
.getOrCreate()
# 假设,现在有这么一组数据
data = [("USA", 1), ("USA", 2), ("India", 1),
("UK", 1), ("India", 4), ("India", 9),
("USA", 8), ("USA", 3), ("India", 4),
("UK", 6), ("UK", 9), ("UK", 5)]
# 创建RDD,并指定分区数
x = spark.sparkContext.parallelize(data, 3)
# 查看分区数
print('分区数: ',y.getNumPartitions())
# 使用groupByKey,默认分区
y = x.groupByKey()
# 查看分区数
print('分区数: ',y.getNumPartitions())
# 使用预定义的分区
y = x.groupByKey(2)
print('分区数: ',y.getNumPartitions())
# 输出结果
for t in y.collect():
print(t[0], list(t[1]))
执行以上代码,输出结果如下:
分区数: 3 分区数: 3 分区数: 2 USA [1, 2, 8, 3] India [1, 4, 9, 4] UK [1, 6, 9, 5]
关于groupByKey,它具有以下特点:
- groupByKey是一个transformation转换操作,因此它的计算是惰性的;
- 它是一种宽依赖的操作,因为它从多个分区shuffle数据并创建另一个RDD;
- 此操作开销很大,因为它不使用分区本地的组合器(combiner)来减少数据传输;
- 当需要对分组数据进行进一步聚合时,不建议使用;
- groupByKey总是会导致对RDD执行哈希分区。
