使用共享变量
除了RDD,Spark中还提供了另一个数据抽象“共享变量”。共享变量可以在并行操作中使用。
默认情况下,当传递给Spark操作(如map或reduce)的函数在远程集群节点上执行时,它会将函数中使用的每个变量的副本发送给每个任务,这些变量被复制到每台机器,而对远程机器上的变量的更新不会传播回驱动程序。但是有时候,我们需要在任务之间共享同一个变量,或者在任务和驱动程序之间共享同一个变量。
Spark支持两种类型的共享变量:广播变量(broadcast variable)和累加器(accumulator),广播变量可用于在所有节点的内存中缓存一个值,累加器是只“添加”到其中的变量,比如计数器和sum。广播变量和累加器能够维护一个全局状态,或者在Spark程序中的任务和分区之间共享数据。
广播变量
广播变量允许程序员在每台机器上保持一个缓存的只读变量,而不是将其副本与任务一起发送。例如,可以使用它们以有效的方式为每个节点提供一个大型输入数据集的副本。Spark还尝试使用高效的广播算法来分发广播变量,以降低通信成本。
广播变量可以从整个集群中共享和访问,但它们不能被executors修改。驱动程序创建一个广播变量,然后executors读取它。 如果有大量的数据,而这些数据是大多数executors所需要的,那么应该使用广播变量。因为默认情况下,在驱动程序中创建的变量,由执行任务所需的任务,被序列化并随这些任务一起发送。但是一个驱动程序可以在几个作业中重用相同的变量,并且一些任务可能会被发送到同一个executor,作为同一作业的一部分。因此,一个潜在的大变量可能会被串行化并在网络上传输超过必要的次数。在这些情况下,最好使用广播变量,因为它们可以以一种更优化的方式传输数据,而且只传输一次。
广播变量是用SparkContext.broadcast(value)方法创建的,它返回一个Broadcast类型的对象。值可以是任何可序列化的对象。然后,executors可以使用Broadcast.value方法读取它。
from pyspark.sql import SparkSession
# 构建SparkSession和SparkContext实例
spark = SparkSession.builder \
.master("spark://xueai8:7077") \
.appName("pyspark demo") \
.getOrCreate()
sc = spark.sparkContext
broadcastVar = sc.broadcast([1, 2, 3])
broadcastVar.value # [1, 2, 3]
当不再需要广播变量时,可以调用destroy()方法销毁它。所有关于它的信息都将被删除(从executors和驱动程序),并且该变量将不可用。如果试图在调用destroy()之后访问它,将抛出一个异常。
另一种方法是调用unpersist()方法,它只从executors的缓存中删除变量值。如果尝试在unpersist()之后使用它,它将再次被发送到executors。
影响广播变量的配置参数有:
- spark.broadcast.compress:spark.io.compression.codec
- spark.broadcast.blockSize:默认是4096
- spark.python.worker.reuse:默认是true
请看下面的示例:
broads = sc.broadcast(3) # 创建广播变量,变量可以是任意类型
lists = [1,2,3,4,5] # 创建一个测试的List
listRDD = sc.parallelize(lists) # 构造一个rdd
results = listRDD.map(lambda x: x * broads.value) # map操作数据
print("结果是: ", results.collect()) # 结果是: [3, 6, 9, 12, 15]
Broadcast VS Cache
Cache也会把数据分发到各个节点,但是一个节点上通常只有部分分区的数据,而Broadcast会保证每个节点都有完整的数据。Broadcast会消耗更多的内存,但是带来了更好的性能。
手动实现broadcast hash join
广播哈希连接(broadcast hash join)将其中一个rdd(较小的rdd)推送到每个工作节点。然后,它对每个较大的分区进行映射端合并。如果一个rdd可以装入内存,或者可以使其装入内存,那么进行广播散列连接总是有益的,因为它不需要shuffle。
PySpark Core没有广播哈希连接的实现。我们可以手动实现广播散列连接的一个版本,方法是将较小的RDD收集到驱动程序中作为一个map,然后广播结果,并使用mapPartitions来组合元素。
Partial manual broadcast hash join
有时候,并不是所有较小的RDD都能装入内存,但是有些键在大数据集中表现得太过了,所以我们希望只广播最常见的键。当一个键太大而不能放在单个分区中时,这就特别有用。在这种情况下,可以在大型RDD上使用countByKeyApprox来大致了解哪些key最能从广播中受益。然后,只针对这些键过滤较小的RDD,并在HashMap中本地收集结果。使用sc.broadcast可以广播HashMap,以便每个worker只有一个副本,并对HashMap手动执行连接。然后,使用相同的HashMap,可以筛选大型RDD,使其不包含大量重复的键,并执行标准连接,将其与手工连接的结果联合起来。这种方法非常复杂,但可以让我们处理用其他方法无法处理的高度倾斜的数据。
累加器
累加器(Accumulators)用来把 executor 端变量信息聚合到 driver 端。在 driver 程序中定义的变量,在 executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后,传回 driver 端进行 merge。
累加器是跨executors之间共享的分布式只写共享变量,每个 executor 之间是不可见的,只有 driver 端可以对其读操作。可以使用它们来实现spark job中的全局求和与计数。
可以创建命名或未命名的累加器。如下图所示,一个指定的累加器(在这个实例计数器中)将显示在web UI中,用于修改该累加器的阶段(stage)。Spark在“Tasks”表中显示由任务修改的每个累加器的值。
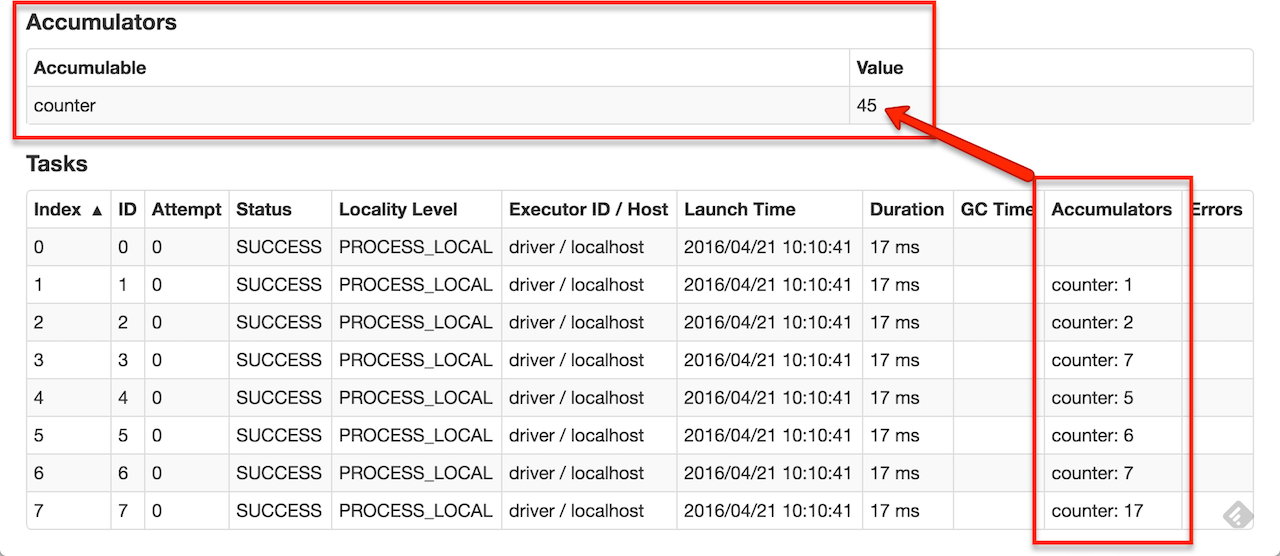
可以通过调用SparkContext.longAccumulator()或SparkContext.doubleAccumulator()来创建数值累加器,以分别累积Long或Double类型的值。然后,可以在task中调用累加器的add方法来修改值。但是,无法在task中读取它的值。只有驱动程序可以通过调用累加器的value方法读取累加器的值。
下面是使用累加器的示例:
acc = sc.accumulator(0) print(acc.value) # 0 list1 = sc.parallelize([1, 2, 3, 4]) # 在executors上执行 list1.foreach(lambda x: acc.add(x)) # 在driver上执行 acc.value # 10
在Spark的执行模型中,只有当计算被触发(例如,由一个action)时,Spark才会添加累加器。
【示例】删除指定数组是既能被2整除也能被3整除的数,并统计删除了多少个。
# 定义计数器
acc = sc.accumulator(0)
# 构造RDD
rdd1 = sc.parallelize(range(1,13))
print(rdd1.collect()) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
# filter method
def filterFun(number):
if (number%2)==0 and (number%3)==0:
acc.add(1)
return False
else:
return True
# filter
rdd2 = rdd1.filter(filterFun).cache()
print(rdd2.collect()) # [1, 2, 3, 4, 5, 7, 8, 9, 10, 11]
print("删除了符合条件的元素有{}个".format(acc.value)) # 删除了符合条件的元素有2个
