案例:运输公司车辆超速实时监测
假设有一个物流公司车队管理解决方案,其中车队中的车辆启用了无线网络功能。每辆运输车需要定期报告其地理位置和多个操作参数,如燃油水平、速度、加速度、轴承、发动机温度等。物流公司希望利用这一远程实时监测数据流来实现一系列应用程序,以帮助他们管理业务的运营和财务方面。
现在我们承担了其中一个任务,需要开发一个流应用程序,实时统计运输车辆每几秒钟的平均速度,用来检查车辆是否超速。程序整体架构如下图所示。

在本案例中,使用Kafka作为流数据源,将从Kafka的cars主题来读取这些事件。同时也将Kafka作为流的Data Sink,检测出的超速事件将写入到Kafka的fastcars主题。
1. 实现技术剖析
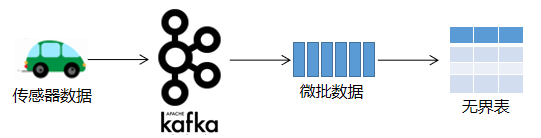
PySpark在处理实时数据流时,它会等待一个非常小的间隔,比如1秒(或者甚至0秒—即尽可能地快)。将在此间隔期间收到的所有事件合并到一个微批处理中。在结构化流中,微批数据被构造为一个流式的DataFrame(即无界表),如下图所示。
这个微批处理然后由驱动程序(Driver)调度,作为任务(Task)在执行器(Executor)中执行。完成微批处理执行后,将再次收集并调度下一批。这种调度是经常进行的,以给人以流执行的印象,如下图所示。

在本案例中使用Kafka作为流数据源,流处理程序将从Kafka的cars主题来读取这些事件,代码如下:
df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "cars") \
.option("startingOffsets", "earliest") \
.load()
为了模拟车辆发送传感器数据,本案例配套源码中提供一个已经创建好的Kafka生产者程序fastcars_fat.jar(这是一个Java程序执行jar包),它将id、speed(速度)、acceleration(加速度) 和timestamp(时间戳)写入Kafka的cars主题。注意,这里的timestamp时间戳是在事件源处生成事件(消息)的时间,即代表事件时间。这个数据源产生过程如图7-13所示。

接下来,在流处理程序中对从Kafka cars主题拉取的原始数据解析解析,这样就有了一个可以使用的结构,代码如下:
# 解析从Kafka拉取的值value
import pyspark.sql.functions as F
convertedDF = df \
.selectExpr("CAST(value as string)") \
.select(F.split("value",",").alias("data")) \
.select(
F.col("data")[0].alias("car_id"),
F.col("data")[1].alias("speed"),
F.col("data")[2].alias("acceleration"),
F.substring(F.col("data")[3],0,10).alias("ts")
) \
.selectExpr(
"car_id",
"CAST(speed as int)",
"CAST(acceleration as double)",
"CAST(ts as bigint)"
) \
.withColumn("ts",F.to_timestamp(F.from_unixtime("ts")))
convertedDF.printSchema()
这时产生的流DataFrame的结构如下图所示。
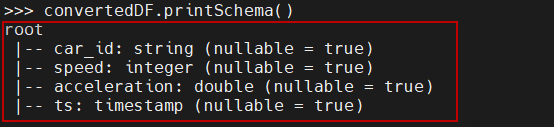
注意,在上面的代码中,因为从Kafka中拉取的数据value值为二进制,所以需要先把它转换为字符串,然后调用split方法将其分割为各个字段。其中模拟数据源生成的日期是13位数字的毫秒值,所以在转换为时间戳之前,需要先调用substring方法截掉最后三位数字(变成10位数字的秒值)。接下来,将各个字段由字符串类型转换为相应的数据类型。
接下来执行聚合操作,这从求每辆车的平均速度开始。这可以通过对car_id执行groupBy()并应用avg()聚合函数来实现,代码如下:
aggregates = convertedDF \
.groupBy("car_id") \
.agg(F.avg("speed"))
在结构化流程序中,可以使用触发器控制微批处理的时间间隔。在PySpark中,触发器被设置为指定在检查新数据是否可用之前等待多长时间。如果没有设置触发器,一旦完成前一个微批处理执行,PySpark将立即检查新数据的可用性。
这里需要计算车辆在过去5秒内的平均速度。为此,需要根据事件时间将事件分组为5秒间隔时间组。这种分组称为窗口。
在PySpark中,窗口是通过在groupBy()子句中添加额外的key来实现的。对于每个消息,它的事件时间(传感器生成的时间戳)用于标识消息属于哪个窗口。基于窗口的类型(滚动/滑动),一个事件可能属于一个或多个窗口。
为了实现窗口化,PySpark添加了一个名为window的新列,并将提供的ts列分解为一个或多个行(基于它的值、窗口的大小和滑动),并在该列上执行groupBy()操作。这将隐式地将属于一个时间间隔的所有事件拉到同一个“窗口”中。
这里根据window和car_id对convertedDF 数据进行分组。注意,window()是PySpark中的一个函数,它返回一个列,代码如下:
# 4秒大小的滚动窗口
aggregates = convertedDF
..groupBy(F.window("ts","4 seconds"), "car_id")
.agg(F.avg("speed").alias("speed"))
.where("speed > 100")
定义窗口大小为4秒、滑动为2秒的滑动窗口,代码如下:
convertedDF.groupBy(F.window("ts", "4 seconds", "2 seconds"), "car_id")
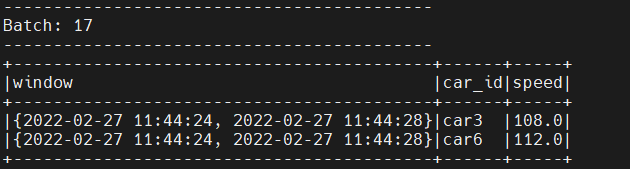
这将产生一个car_id、平均速度和相应时间窗口的DataFrame。输出如下图所示。
PySpark提供了三种输出模式:complete、update和append。在处理微批处理后,PySpark更新状态和输出结果的方式各不相同,如下图所示。

在每个微批处理期间,PySpark更新前批处理中的一些key的值,有些是新的,有些保持不变。在complete模式下,输出所有的行,而在update模式下,只输出新的和更新的行。append模式略有不同,在append模式中,不会有任何更新的行,它只输出新增的行。在流程序中指定输出模式,代码如下:
writeToKafka = aggregates \
.selectExpr("CAST(car_id as string) as key", "warn as value") \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers","xueai8:9092") \
.option("topic", "fastcars") \
.option("startingOffsets", "earliest") \
.option("checkpointLocation", "/tmp/carsck/") \
.outputMode("update") \
.start()
在使用Kafka接收器时,检查点位置是必须的,它支持故障恢复和精确地一次处理。
运行应用程序的输出如下图所示。

请注意,结构化流API隐式地跨批维护聚合函数的状态。例如,在上面的例子中,第二个微批计算的平均速度将是第1和第2批接收到的事件的平均速度。作为用户,我们不需要自定义状态管理。但随着时间的推移,维护一个庞大的状态也会带来成本。这可以通过使用水印来实现控制。
在PySpark中,水印用于根据当前最大事件时间决定何时清除状态。基于用户所指定的延迟,水印滞后于目前所看到的最大事件时间。例如,如果dealy是3秒,当前最大事件时间是10:00:45,那么水印是在10:00:42。这意味着Spark将保持结束时间小于10:00:42的窗口的状态。在程序中指定水印,代码如下:
# 使用ts字段设置水印,最大延迟为3s
aggregates = convertedDF \
.withWatermark("ts", "3 seconds") \
.groupBy(F.window("ts","4 seconds"), "car_id") \
.agg(F.avg("speed").alias("speed")) \
.where("speed > 100") \
.withColumn("warn",F.concat_ws(", ","car_id","speed"))
需要理解的一个细微但重要的细节是,当使用基于EventTime的处理时,只有当接收到具有更高时间戳值的消息/事件时,时间才会前进。可以将它看作PySpark内部的时钟,但与每秒钟滴滴计时(基于处理时间)的普通时钟不同,该时钟只在接收到具有更高时间戳的事件时移动。
请看下面这个示例,以深入理解在消息到达较迟时PySpark引擎会如何去处理。这里将集中于[10:00到10:10]之间的单个窗口和5秒的最大延迟,代码如下:
.withWatermark("ts", "5 seconds")
引擎跟踪的最大事件时间,在每个触发器开始时将水印设置为(最大事件时间-5秒钟)。如下图所示。
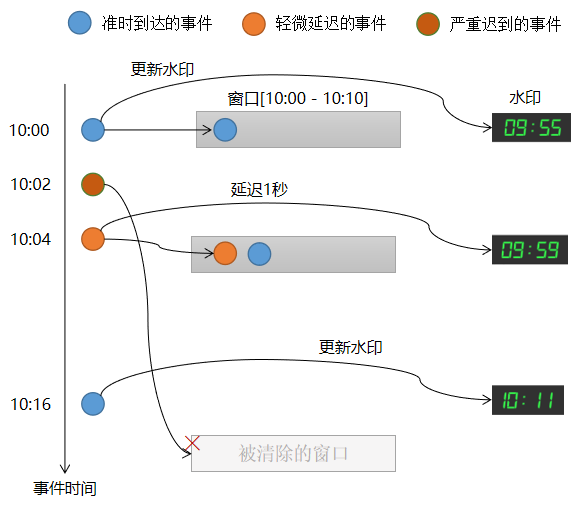
对于上图,说明如下:
- (1) 一个时间戳为10:00的事件到达并落在窗口[10:00,10:10),水印被更新为timestamp - 5。
- (2) 在数据源处生成时间戳为10:02的事件,但该事件会有很大的延迟。这个事件应该落在窗口[10:00,10:10)中。
- (3) 时间戳为10:04的事件在10:05时到达,稍微有些延迟,但它仍然落在窗口[10:00,10:10)中,因为当前水印为09:55,即小于窗口结束时间。水印更新到10:04 - 00:05 = 09:59。
- (4) 一个时间戳为10:16的事件到达,它将水印更新为10:11(此事件将落在窗口[10:10,10:20),但与这里讨论的内容不相关)。
- (5) 带有时间戳10:02的延迟事件姗姗来迟,但是此时窗口[10:00,10:10)已经被清除,因此该事件将被删除。
设置水印将确保状态不会永远增长。另外,请注意本示例中一个延迟事件是如何处理的,而另一个是如何被忽略了(因为已经太迟了)。
2. 完整实现代码
下面给出本案例的完整代码。
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import pyspark.sql.functions as F
# 创建SparkSession实例
spark = SparkSession.builder.appName("Cars Demo").getOrCreate()
# 设置shuffle后的分区数为10(测试环境下)
spark.conf.set("spark.sql.shuffle.partitions",10)
# 设置日志级别
# spark.sparkContext.setLogLevel("WARN")
# 创建一个流来监听cars topic的消息
df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "xueai8:9092") \
.option("subscribe", "cars") \
.option("startingOffsets", "earliest") \
.load()
# 查看schema
df.printSchema()
# 解析从Kafka拉取的值value
convertedDF = df \
.selectExpr("CAST(value as string)") \
.select(F.split("value",",").alias("data")) \
.select(
F.col("data")[0].alias("car_id"),
F.col("data")[1].alias("speed"),
F.col("data")[2].alias("acceleration"),
F.substring(F.col("data")[3],0,10).alias("ts")
) \
.selectExpr(
"car_id",
"CAST(speed as int)",
"CAST(acceleration as double)",
"CAST(ts as bigint)"
) \
.withColumn("ts",F.to_timestamp(F.from_unixtime("ts")))
convertedDF.printSchema()
# 执行不带窗口的聚合
# aggregates = convertedDF.groupBy("car_id").agg(F.avg("speed"))
# 执行滑动窗口聚合,窗口定义:大小为4秒、滑动为1秒
# convertedDF.groupBy(F.window("ts","4 seconds","1 seconds"), "car_id")
# 如果使用处理时间
# convertedDF.groupBy(window(current_timestamp(),"4 seconds"), "car_id")
# 执行带有水印的窗口聚合
aggregates = convertedDF \
.withWatermark("ts", "3 seconds") \
.groupBy(F.window("ts","4 seconds"), "car_id") \
.agg(F.avg("speed").alias("speed")) \
.where("speed > 100") \
.withColumn("warn",F.concat_ws(", ","car_id","speed"))
aggregates.printSchema()
# 将结果写出到控制台
writeToConsole = aggregates \
.writeStream \
.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.start()
# 将结果写出到Kafka
writeToKafka = aggregates \
.selectExpr("CAST(car_id as string) as key", "warn as value") \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers","xueai8:9092") \
.option("topic", "fastcars") \
.option("startingOffsets", "earliest") \
.option("checkpointLocation", "/tmp/carsck/") \
.outputMode("update") \
.start()
# 等待多个流结束(作为作业文件提交集群上运行时启用)
# 在pyspark shell命令行,在查询对象上调用.stop()方法停止查询
# spark.streams.awaitAnyTermination()
3. 执行步骤演示
本案例涉及到与Kafka的集成,以及使用自定义的数据源程序,所以执行步骤稍稍有点复杂,请按以下说明操作。
1) 测试数据源
本案例使用到一个Kafka生产者程序。该程序是以Java开发、编译和打包的执行jar包,它位于配套的源码包中,名为fastcars_fat.jar,可使用jar命令来运行它。请按以下步骤测试和掌握该数据源程序的使用。
(1) 启动zookeeper。在第一个终端窗口,执行以下命令:
$ cd ~/bigdata/kafka_2.12-2.4.1 $ ./bin/zookeeper-server-start.sh config/zookeeper.properties
这将在2181端口启动ZooKeeper进程,并让ZooKeeper在后台工作。
(2) 接下来,启动Kafka服务器。在第二个终端窗口,执行以下命令:
$ cd ~/bigdata/kafka_2.12-2.4.1 $ ./bin/kafka-server-start.sh config/server.properties
(3) 创建主题cars。在第三个终端窗口,执行以下命令:
$ cd ~/bigdata/kafka_2.12-2.4.1 $ ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic cars # 查看已有的主题: $ ./bin/kafka-topics.sh --list --zookeeper localhost:2181
(4) 运行kafka消费者脚本,指定要连接的Kafka服务器名称和端口号,以及要连接的主题。继续在第三个终端窗口,执行以下命令:
$ ./bin/kafka-console-consumer.sh --topic cars --bootstrap-server localhost:9092
(5) 运行模拟数据源程序jar包。打开第四个终端窗口,执行以下命令:
$ java -jar ~/jars/fastcars_fat.jar localhost:9092 cars
其中参数localhost:9092是要连接的Kafka服务器名称和端口号,参数cars是连接的主题。这两个参数可以根据自己的需要修改,但是要和消费者监听的服务器和主题一致。
执行过程如下图所示。

(6) 回到第三个终端窗口(运行消费者脚本的窗口),可以看到输出了接收到的数据信息,如下图所示。

(7) 如果要终止数据源程序或消费者脚本的运行,同时按下Ctrl + C键即可。
2) 执行流程序
接下来,就可以运行上节开发的PySpark结构化流程序,来实时监测运输车辆的车速,并及时将监测到的超速车辆信息发送到Kafka的fastcars主题。请按以下步骤操作。
(1) 启动zookeeper(如果已经启动,略过此步骤)。在第一个终端窗口,执行以下命令:
$ cd ~/bigdata/kafka_2.12-2.4.1 $ ./bin/zookeeper-server-start.sh config/zookeeper.properties
(2) 接下来,启动Kafka服务器(如果已经启动,略过此步骤)。在第二个终端窗口,执行以下命令:
$ cd ~/bigdata/kafka_2.12-2.4.1 $ ./bin/kafka-server-start.sh config/server.properties
(3) 创建主题fastcars(如果已经创建,略过此步骤)。在第三个终端窗口,执行以下命令:
$ cd ~/bigdata/kafka_2.12-2.4.1 $ ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic fastcars # 查看已有的主题: $ ./bin/kafka-topics.sh --list --zookeeper localhost:2181
(4) 运行kafka消费者脚本,监听超速车辆信息。继续在第三个终端窗口,执行以下命令:
$ ./bin/kafka-console-consumer.sh --topic fastcars --bootstrap-server xueai8:9092
(5) 运行流程序。打开第四个终端窗口,启动pyspark shell,运行上节开发的流程序代码。(也可以保存到.ipynb文件中,使用spark-submit命令提交执行)
(6) 运行模拟数据源程序jar包。打开第五个终端窗口,执行以下命令:
$ java -jar ~/jars/fastcars_fat.jar localhost:9092 cars
(7) 回到第三个终端窗口,如果一节正常,那么可以看到接收到的超速信息,如下图所示。

(8) 如果要结束程序的运行,按以下顺序关闭:
- 第一步,先关闭数据源程序,同时按下Ctrl + C键。
- 第二步,再关闭流处理程序,键入exit()函数,然后按下Enter键。
- 第三步,然后关闭消费者脚本程序,同时按下Ctrl + C键。
- 第四步,先关闭Kafka集群,同时按下Ctrl + C键。
- 第五步,最后关闭Zookeeper集群,同时按下Ctrl + C键。