使用Jupyter Notebook进行交互式分析
数据分析师最喜欢的一个交互式分析工具是Jupyter Notebook,因此也希望在应用Spark进行大数据分析时也使用Jupyter。下面我们就配置PySpark与Jupyter的组合。
有两种方法可以使PySpark在Jupyter Notebook中可用:
- 配置PySpark驱动程序使用Jupyter Notebook:运行pyspark将自动打开一个Jupyter Notebook。
- 加载一个普通的Jupyter Notebook,并使用findSpark包加载PySpark。
第一种方法更快,但是特定于Jupyter笔记本;第二种方法是一种更广泛的方法,可以在自己喜欢的IDE中使用PySpark。
配置PySpark Driver使用Jupyter Notebook
请按以下步骤配置和启动Spark及Jupyter Notebook。
1)启动Spark集群:
$ cd ~/bigdata/spark-3.1.2 $ ./sbin/start-all.sh
2)指定驱动程序(driver)使用Jupyter Notebook。在终端窗口中,执行如下命令:
$ export PYSPARK_DRIVER_PYTHON="jupyter" $ export PYSPARK_DRIVER_PYTHON_OPTS="notebook --no-browser --ip=0.0.0.0"
注意,如果你是以root账户在进行操作,则还需要加上“--allow-root”参数,将上述第二行命令修改如下:
$ export PYSPARK_DRIVER_PYTHON_OPTS="notebook --allow-root --no-browser --ip=0.0.0.0"
3)使用cd命令进入到notebook文档存放的目录位置,然后启动pyspark shell。在终端窗口中,执行如下命令:
$ mkdir pyspark_demos $ cd pyspark_demos $ pyspark --master spark://xueai8:7077
如下图所示:
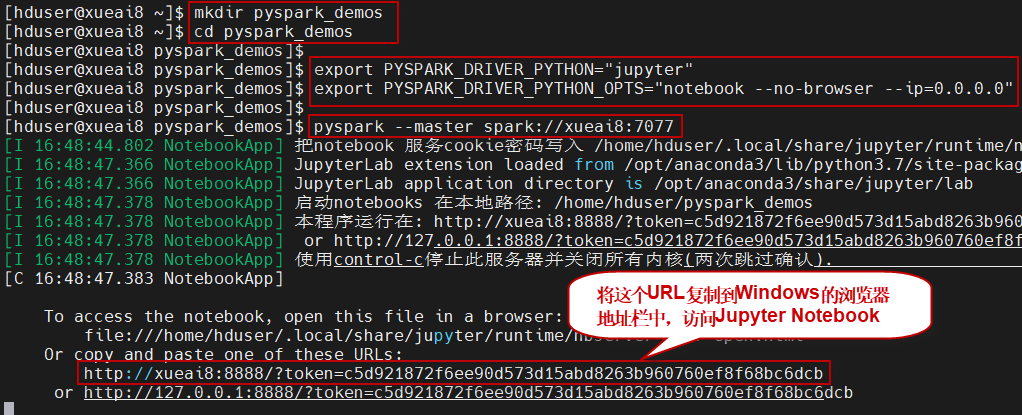
注意,不要关闭此窗口,保持服务一直处于运行状态。
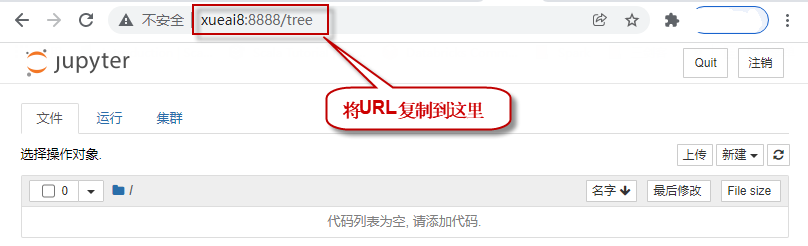
4)在Windows下,通过浏览器访问Jupyter。到Windows下,打开浏览器,粘贴上一步复制的URL,回车访问,打开notebook页面。如下图所示:
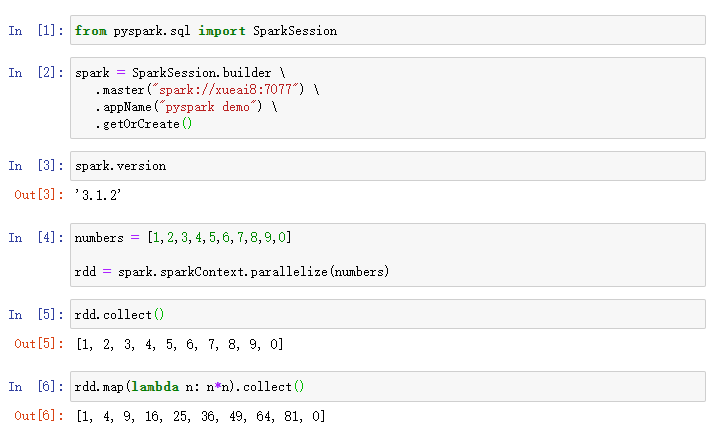
5)编写PySpark代码。新建一个notebook,输入以下代码执行:
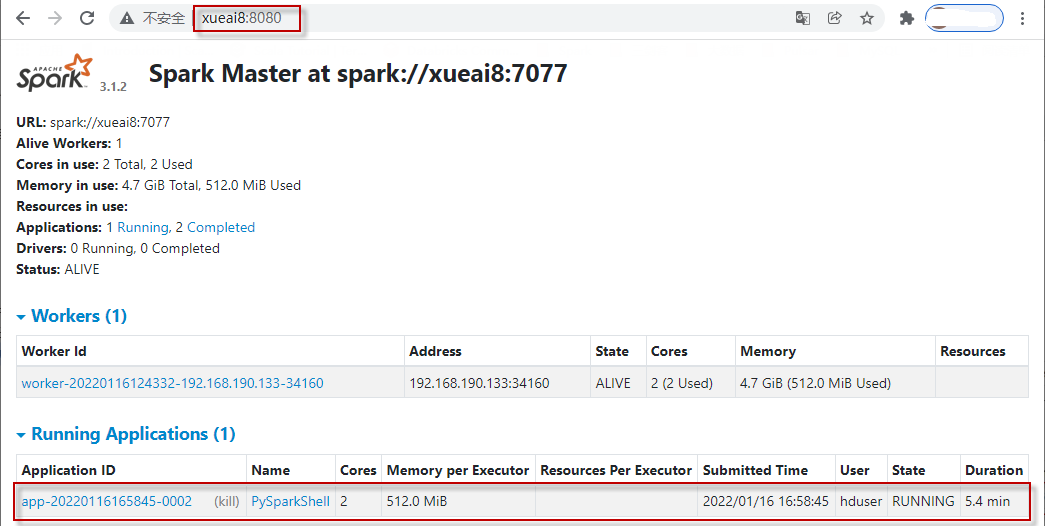
6)查看Spark Web UI。另打开一个浏览器窗口,访问http://xueai8:8080。如下图所示:
7)查看正在执行的Spark作业的Web UI。另打开一个浏览器窗口,访问http://xueai8:4040,可以看到正在执行和已经执行完成的作业情况。如下图所示:
使用findSpark包
在Jupyter笔记本中使用PySpark还有另一种方法是,使用findSpark包使Spark上下文在代码中可用。
findSpark包不是特定于Jupyter笔记本的,我们也可以在自己喜欢的IDE中使用这个技巧。
1)首先安装findSpark包:
$ sudo /opt/anaconda3/bin/pip install findspark
2)然后在终端输入jupyter notebook即可:
$ jupyter notebook --no-browser --ip=0.0.0.0
3)在代码中初始化一下即可:
import findspark findspark.init()
然后正常的PySpark编码即可。
4)新建一个Python 3程序文件,执行如下代码:
from pyspark.sql import SparkSession
# 创建SparkSession实例,这是PySpark程序入口
spark = SparkSession.builder.master("spark://xueai8:7077").appName("pyspark_demo").getOrCreate()
# 查看Spark版本号
spark.version
# 构造一个RDD
rdd = spark.sparkContext.parallelize(range(10))
rdd.collect()
# 查看RDD的分区数
rdd.getNumPartitions()
课程章节 返回课程首页
-
Ch01 Spark架构与集群搭建
-
Ch02 开发和部署PySpark程序
-
Ch03 PySpark核心编程
-
Ch04 PySpark SQL编程(初级)
-
Ch05 PySpark SQL编程(高级)
-
Ch06 PySpark结构化流处理(初级)
-
Ch07 PySpark结构化流处理(高级)
-
ch08 PySpark大数据分析综合案例