发布日期:2022-07-30
VIP内容
PySpark SQL可视化
PySpark还没有任何绘图功能。如果想绘制一些内容,可以将数据从SparkContext中取出并放入“本地”Python会话中,在那里可以使用Python的任意一个绘图库来处理它。
对于PySpark SQL中的DataFrame,可以先将它转成Pandas的DataFrame,再应用Python绘图库进行绘制。
1. PySpark DataFrame转换到Pandas
在PySpark中,很容易通过一行代码将PySpark DataFrame转换为Pandas DataFrame,代码如下:
df_pd = df.toPandas()
在下面的示例中,演示了如何将PySpark DataFrame Row对象列表转换为Pandas DataFrame,代码如下:
from pyspark.sql import SparkSession
from pyspark.sql.functions import collect_list,struct
from pyspark.sql.types import *
from decimal import Decimal
import pandas as pd
# 构建SparkSession实例
spark = SparkSession.builder \
.master("spark://localhost:7077") \
.appName("pyspark rdd demo") \
.getOrCreate()
# List
data = [ ('Category A', 1, Decimal(12.40)),
('Category B', 2, Decimal(30.10)),
('Category C', 3, Decimal(100.01)),
('Category A', 4, Decimal(110.01)),
('Category B', 5, Decimal(70.85))
]
# 创建schema
schema = StructType([
StructField('Category', StringType(), False),
StructField('ItemID', IntegerType(), False),
StructField('Amount', DecimalType(scale=2), True)
])
# 将List转换为RDD
rdd = spark.sparkContext.parallelize(data)
# 创建DataFrame
df = spark.createDataFrame(rdd, schema)
df.printSchema()
df.show()
# 将PySpark DataFrame转换为Pandas DataFrame
df_pd = df.toPandas()
df_pd.info()
# 查看Pandas DataFrame
print(df_pd)
执行以上代码,PySpark DataFrame的输出内容如下:
root |-- Category: string (nullable = false) |-- ItemID: integer (nullable = false) |-- Amount: decimal(10,2) (nullable = true) +----------+------+------+ | Category|ItemID|Amount| +----------+------+------+ |Category A| 1| 12.40| |Category B| 2| 30.10| |Category C| 3|100.01| |Category A| 4|110.01| |Category B| 5| 70.85| +----------+------+------+
Pandas DataFrame的信息输出如下:
RangeIndex: 5 entries, 0 to 4 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Category 5 non-null object 1 ItemID 5 non-null int32 2 Amount 5 non-null object dtypes: int32(1), object(2) memory usage: 228.0+ bytes
Pandas DataFrame的内容输出如下:
Category ItemID Amount 0 Category A 1 12.40 1 Category B 2 30.10 2 Category C 3 100.01 3 Category A 4 110.01 4 Category B 5 70.85
2. PySpark SQL DataFrame可视化
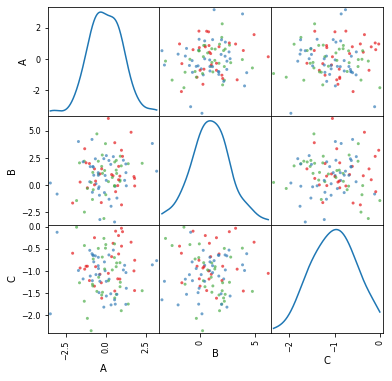
对于PySpark SQL的DataFrame绘图,用户可以先将它转成Pandas的DataFrame,再绘制。在下面的这个示例中,创建了一个包含3个正态分布数字列和一个颜色类别列的DataFrame,然后将其转换为Pandas的DataFrame,并进行可视化绘图展示,代码如下:
from pyspark.sql import SparkSession
import random
# 构建SparkSession实例
spark = SparkSession.builder \
.master("spark://xueai8:7077") \
.appName("pyspark sql demo") \
.getOrCreate()
# 创建一个包含3个数字列和一个类别(颜色)的spark dataframe
A = [random.normalvariate(0,1) for i in range(100)]
B = [random.normalvariate(1,2) for i in range(100)]
C = [random.normalvariate(-1,0.5) for i in range(100)]
col = [random.choice(['#e41a1c', '#377eb8', '#4eae4b']) for i in range(100)]
df = spark.createDataFrame(zip(A,B,C,col), ["A","B","C","col"])
df.printSchema()
df.show(5)
from pandas.plotting import scatter_matrix
# 转换为pandas并绘图
pdf = df.toPandas()
stuff = scatter_matrix(pdf, alpha=0.7, figsize=(6, 6), diagonal='kde', color=pdf.col)
执行以上代码,输出的PySpark SQL DataFrame内容如下:
root |-- A: double (nullable = true) |-- B: double (nullable = true) |-- C: double (nullable = true) |-- col: string (nullable = true) +-------------------+--------------------+--------------------+-------+ | A| B| C| col| +-------------------+--------------------+--------------------+-------+ | 1.384946838507259| 1.9723595337779216| -1.7433008332887872|#4eae4b| |-0.9812217969597337| 1.7046046382241848| -1.113379241508142|#377eb8| | 0.575954311201969|-0.10590577165060955| -1.7451690616923745|#377eb8| |-1.0115365029459253| 0.30510247214884667| -0.5342195326699025|#377eb8| |-3.0459506903597946| -0.8299767662273825|-0.12795069365362288|#377eb8| +-------------------+--------------------+--------------------+-------+ only showing top 5 rows
转换为Pandas DataFrame后,绘制结果如下图所示: