使用Zeppelin进行交互式分析
Apache Zeppelin是一款基于Web的NoteBook,支持交互式数据分析。使用Zeppelin,可以使用丰富的预构建语言后端(或解释器)制作精美的数据驱动、交互式和协作文档。目前,Apache Zeppelin支持Apache Spark、Python、JDBC、Markdown和Shell等多种解释器。
特别是,Apache Zeppelin提供了内置的Apache Spark集成。我们不需要为它构建单独的模块、插件或库。Apache Zeppelin与Spark集成,提供了如下功能:
- 自动注入SparkContext和SQLContext;
- 从本地文件系统或maven存储库加载运行时jar依赖项;
- 取消作业并显示进度。
Apache Zeppelin专注于企业级应用,Zeppelin Notebook可以满足以下企业用户以下需求:
- 数据摄取
- 数据发现
- 数据分析
- 数据可视化与协作
接下来,我们学习如何安装Zeppelin和配置Zeppelin解释器,并演示如何使用Zepplin Notebook作为Spark的交互式数据分析工具进行大数据的分析和数据可视化。
下载zeppelin安装包
Apache Zeppelin的下载地址为:http://zeppelin.apache.org/download.html。请选择图中所示的版本:
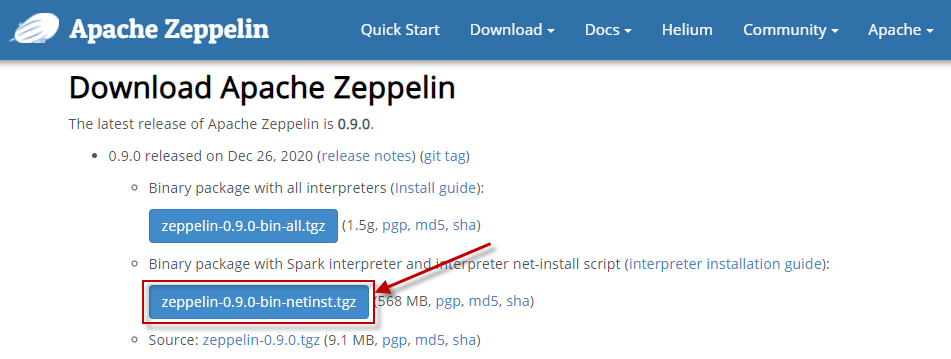
将下载的安装包拷贝到~/software目录下。
安装和配置Zeppelin
请按以下步骤安装和配置Zeppelin。
1)将下载的安装包解压缩到~/bigdata目录下,并改名为zeppelin-0.9.0:
$ cd ~/bigdata $ tar xvf ~/software/zeppelin-0.9.0-bin-netinst.tgz $ mv zeppelin-0.9.0-bin-netinst zeppelin-0.9.0
2)配置环境变量:
$ cd $ sudo nano /etc/profile
在文件最后,添加如下内容:
export ZEPPELIN_HOME=/home/hduser/bigdata/zeppelin-0.9.0 export PATH=$PATH:$ZEPPELIN_HOME/bin
保存文件并关闭。
3)执行/etc/profile文件使得配置生效:
$ source /etc/profile
4)打开conf/zeppelin-env.sh文件:(默认没有,从模板复制一份)
$ cd ~/bigdata/zeppelin-0.9.0/conf $ cp zeppelin-env.sh.template zeppelin-env.sh $ nano zeppelin-env.sh
在文件最后添加如下几行内容:
export JAVA_HOME=/opt/java/jdk1.8.0_281 export SPARK_HOME=/home/hduser/bigdata/spark-3.1.2 export HADOOP_HOME=/home/hduser/bigdata/hadoop-3.2.2 export HADOOP_CONF_DIR=/home/hduser/bigdata/hadoop-3.2.2/etc/hadoop export PYSPARK_PYTHON=/opt/anaconda3/bin/python export PYSPARK_DRIVER_PYTHON=/opt/anaconda3/bin/python export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9-src.zip
5)打开zeppelin-site.xml文件:(默认没有,从模板复制一份)
$ cd ~/bigdata/zeppelin-0.9.0/conf $ cp zeppelin-site.xml.template zeppelin-site.xml $ nano zeppelin-site.xml
修改如下两个属性,设置新的端口号,以避免与Spark Web UI默认端口发生冲突:
<property> <name>zeppelin.server.port</name> <value>9090</value> <description>Server port.</description> <property> <name>zeppelin.server.ssl.port</name> <value>9443</value> <description>Server ssl port. (used when ssl property is set to true)</description> </property>
6)启动zeppelin服务
在终端窗口中,执行以下命令,启动zeppelin服务:
$ zeppelin-daemon.sh start
执行如下图所示:

7)关闭zeppelin服务
在终端窗口中,执行以下命令,停止zeppelin服务:
$ zeppelin-daemon.sh stop
配置Spark解释器
说明:如果是使用Spark local模式,此一步骤省略。如果是使用Spark standalone模式,需要配置Spark解释器。
首先启动浏览器,在浏览器地址栏输入URL:http://xueai8:9090/,打开访问界面,如下图。点击右上角的小三角按钮,打开下拉菜单,点击“Interpreter”菜单项,打开解释器配置界面。

打开的解释器配置界面如下图所示。按图中所示找到spark解释器,添加一个SPARK_HOME属性,然后修改master属性值为spark://xueai8:7077(这实际上是连接到的集群管理器,这里我们使用的是spark standalone模式。这相当于启动pyspark shell时指定--master参数)。

再新增加两个PySpark Python的相关设置,如下图所示。

然后单击【Save】按钮保存。
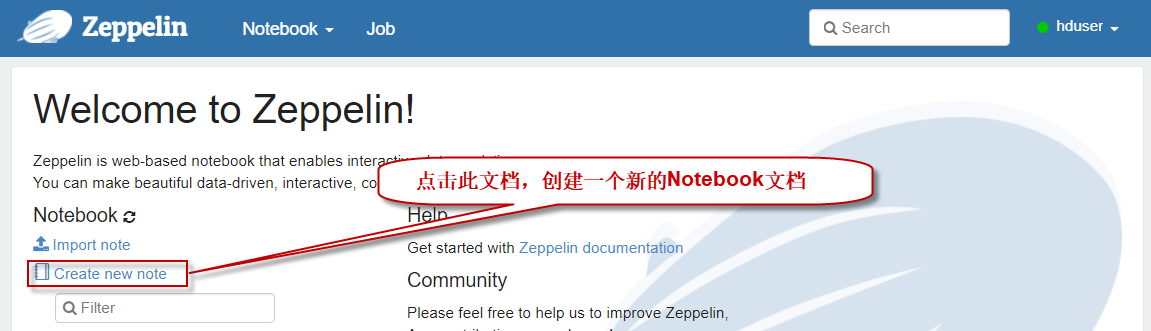
创建和执行notebook文件
回到浏览器zeppelin首页,点击按钮,创建一个新的notebook文件,如下图所示:
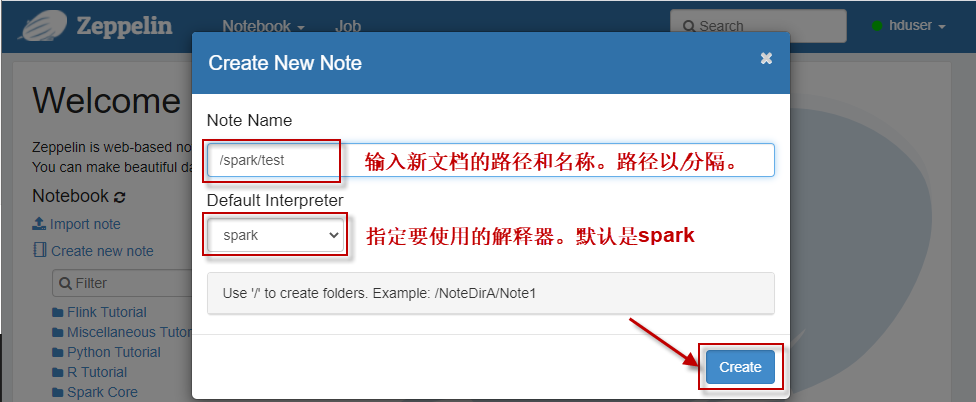
然后在弹出的创建窗口,填写相应信息,然后单击【Create】按钮即可:
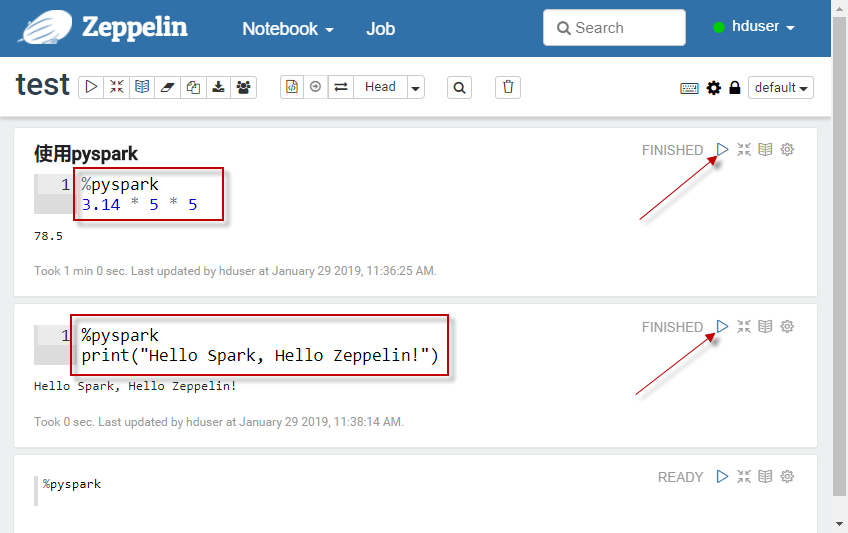
执行Spark交互式操作-Python语言
在新打开的notebook界面,执行Python代码。需要在第一行键入“%pyspark”,以告诉zeppelin使用pyspark解释器。如下图所示: