某招聘网站招聘大数据分析案例(爬虫 + HDFS + PySpark + Hive数仓 + Flask框架(jinja2) + ECharts)
项目描述
本章的综合案例涉及数据的采集(使用爬虫程序)、数据集成、数据预处理、大数据存储、Hive数据仓库应用、大数据ELT实现和大数据结果展现等全流程所涉及的各种典型操作,涵盖Linux、MySQL、Hadoop 3、Flume、PySpark 3.x.x、Hive、Flask Web框架、ECharts组件和PyCharm、Zeppelin Noebook等系统和软件的使用方法。通过本项目,将有助于读者综合运用主流大数据技术以及各种工具软件,掌握大数据离线批处理的全流程操作。
项目架构
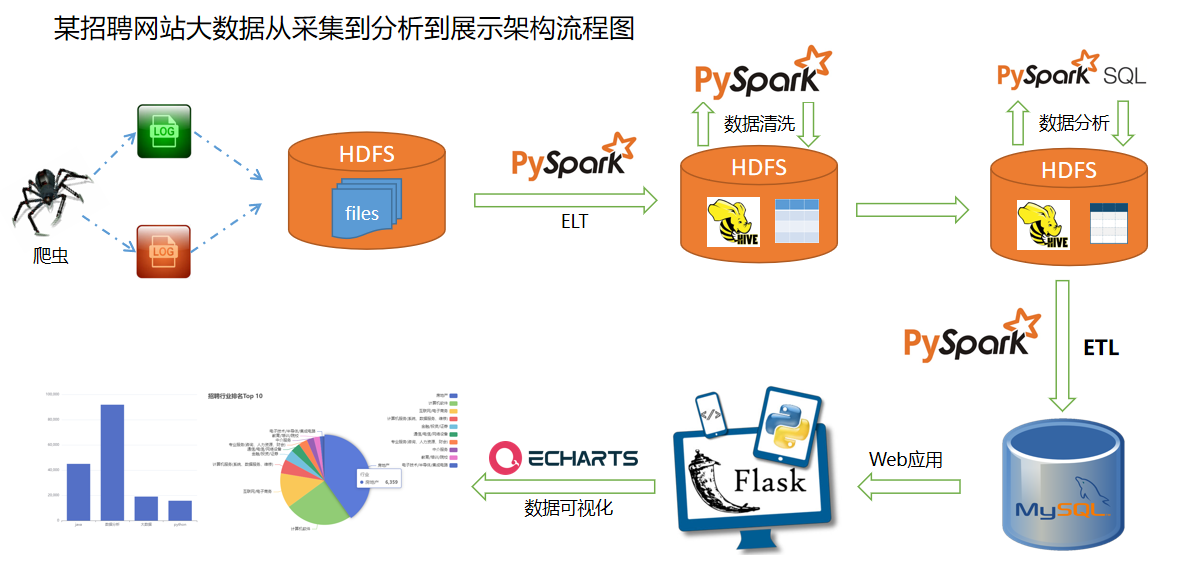
项目流程
项目流程说明如下:
- 1. 数据采集:使用Python爬虫程序爬取某知名招聘企业网站上公开的招聘数据;
- 2. 数据集成:使用Flume自动监测并导入采集到的数据文件到HDFS中存储;
- 3. 数据ELT:使用PySpark建立ELT管道,将集成到的数据文件导入到Hive数据仓库中ODS层;
- 4. 数据清洗:使用PySpark + Hive进行数据清洗和整理;
- 5. 数据分析:使用PySpark SQL + Hive进行数据多维度分析;
- 6. 分析结果导出:使用PySpark建立ETL管道,将分析结果导出到MySQL数据库;
- 7. 分析结果可视化:使用Python Flask + jinja2模板 + ECharts实现分析结果网页可视展示。
适用对象
本项目适合以下人员学习使用:
- 已有Spark/Python基础,需要掌握大数据完整开发和分析流程、积累大数据项目经验;
- 大数据专业毕业设计项目。
项目实施过程
1. 数据采集本项目提供两套实现代码(requets实现和scrapy框架实现),实现从某招聘网站采集北、上、广、深、杭五个一线城市热门岗位的最新招聘信息。用户可在这基础上,修改要爬取的城市和岗位,满足自己的需求。
2. 数据集成掌握Flume组件的配置和使用。使用Flume自动监测并导入采集到的数据文件到HDFS中存储。这一步是可选的,用户根据自己的要求决定是否采用。如果没有要求,也可以直接采用hdfs命令上传采集到的数据到HDFS上存储。
3. 数据ELT使用PySpark建立ELT管道,抽取HDFS上存储的数据文件并装载到Hive数据仓库的ODS层。过程这个任务,用户可掌握使得PySpark构造ELT或ETL管道的技术。
4. 大数据清洗使用PySpark对Hive ODS中的数据进行清洗,包括去重、错误数据处理、空值处理、属性转换、属性提取等数据预处理任务。将预处理过后的数据存储Hive DW层。
5. 大数据分析使用PySpark SQL从多个维度对整理后的数据集进行分析,并将分析结果存入到Hive的数据集市。
6. 分析结果导出使用PySpark SQL建立ETL管道,将分析结果导出到MySQL数据库;
7. 分析结果可视化使用Python Flask + jinja2模板 + ECharts构建Web项目,将分析结果在网页中通过Echarts组件进行可视展示。
您还未登录!(正式会员登录后可下载)
项目视频讲解
请点击下方链接,选择要播放的讲解视频。(注:正式用户登录方可观看全部项目视频)
本项目尚未提供讲解视频,请通过下载的文档和代码学习!