Hive QL窗口函数
在Hive高级分析函数中,提供了在逻辑分组中执行聚合的能力,这个逻辑分组被称为窗口。
有时需要对一组数据进行操作,并为每个输入行返回一个值,而窗口函数提供了这种独特的功能,使其易于执行计算,如移动平均、累积和或每一行的rank排名。
Hive窗口函数语法
窗口函数出现在 SELECT 子句的表达式列表中,它最显著的特点就是 OVER 关键字。语法定义如下:
Function (arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>] [其中Function (arg1,…, argn) 可以是下面的函数:])
- Aggregate Functions:聚合函数,比如sum(…)、 max(…)、min(…)、avg(…)等。
- Sort Functions:数据排序函数,比如rank(…)、row_number(…)等。
- Analytics Functions:统计和比较函数,比如lead(…)、lag(…)、 first_value(…)等。
而窗口规范由over关键字来定义:
OVER ([PARTITION BY <...>] [ORDER BY <....>] [])
over()窗口规范定义了窗口函数将使用的三个重要组件。
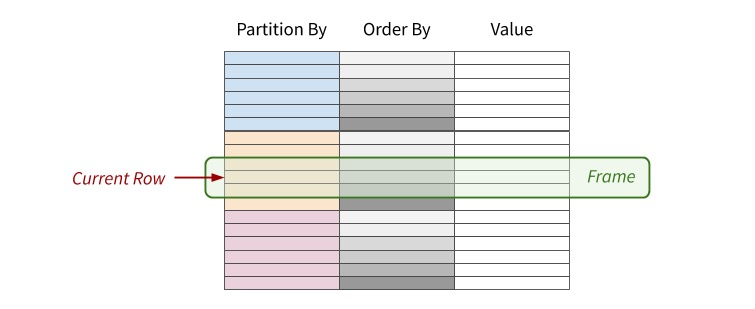
- 第一个组件被称为partition by,指定用来对行进行分组的列(一个或多个列)。它表示将数据先按字段进行分区。
- 第二个组件称为order by,它定义了如何根据一个或多个列来排序各行,以及是升序或降序。它表示将各个分区内的数据按排序字段进行排序。
- 第三个组件称为window_expression,它定义了窗口相对于当前行的边界。换句话说,指定窗口范围rows between 开始位置 and 结束位置,通常也称为frame。
上面三个组件当中,最后一个组件是可选的,有的窗口函数需要,有的窗口函数或场景不需要。
具体来说:
- 如果不指定partition by,则不对数据进行分区。换句话说,所有数据看作同一个分区;
- 如果不指定order by,则不对各分区做排序,通常用于那些顺序无关的窗口函数,例如sum();
- 如果不指定window_expression,则默认采用以下的窗口定义:
- 若未指定order by,默认使用分区内所有行rows between unbounded preceding and unbounded following;
- 若指定了order by,默认使用分区内第一行到当前行rows between unbounded preceding and current row。
窗口边界
窗口函数定义规范中的第三个组件window_expression用于确定窗口边界,如下图所示:
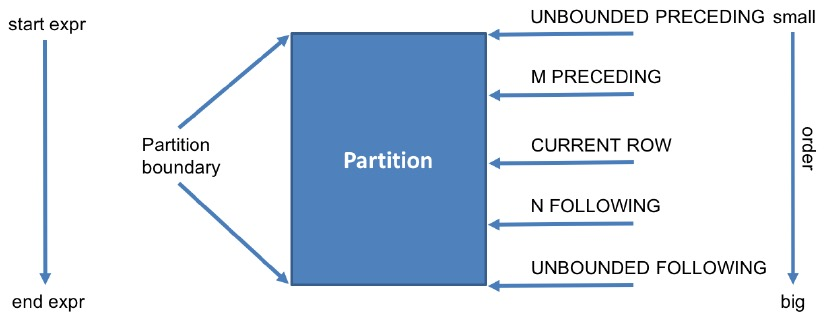
其中涉及到的边界定义含义如下表所示:
| 名词 | 含义 |
|---|---|
| preceding | 往前 |
| following | 往后 |
| current row | 当前行 |
| unbounded | 无边界的,起点或终点 |
| unbounded preceding | 从前面的起点 |
| unbounded following | 到后面的终点 |
窗口函数的计算过程
窗口函数在执行时,按以下顺序:
- 1)按窗口定义,将所有输入数据分区、再排序(如果需要的话);
- 2)对每一行数据,计算它的窗口范围;
- 3)将窗口内的行集合输入窗口函数,计算结果填入当前行;
窗口函数应用示例
下面我们通过一个示例演示Hive各个窗口函数的使用方法。
1. 准备数据
创建Hive表:
CREATE TABLE IF NOT EXISTS q1_sales (
emp_name string,
emp_mgr string,
dealer_id int,
sales int,
stat_date string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED as TEXTFILE;
插入测试数据:
insert into table q1_sales (emp_name,emp_mgr,dealer_id,sales,stat_date)
values
('Beverly Lang','Mike Palomino',2,16233,'2020-01-01'),
('Kameko French','Mike Palomino',2,16233,'2020-01-03'),
('Ursa George','Rich Hernandez',3,15427,'2020-01-04'),
('Ferris Brown','Dan Brodi',1,19745,'2020-01-02'),
('Noel Meyer','Kari Phelps',1,19745,'2020-01-05'),
('Abel Kim','Rich Hernandez',1,12369,'2020-01-03'),
('Raphael Hull','Kari Phelps',1,8227,'2020-01-02'),
('Jack Salazar','Kari Phelps',1,9710,'2020-01-01'),
('May Stout','Rich Hernandez',3,9308,'2020-01-05'),
('Haviva Montoya','Mike Palomino',2,9308,'2020-01-03');
查看测试数据信息
select * from q1_sales;
查询结果如下:
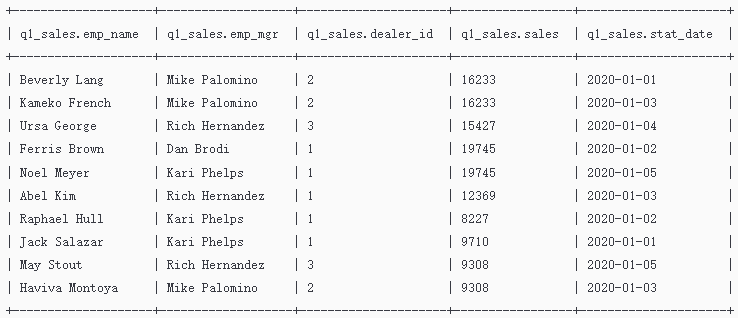
2. 执行窗口聚合运算
Hive支持的窗口聚合函数如下表所示:
| 窗口函数 | 返回类型 | 函数描述 |
|---|---|---|
| AVG() | 参数类型为DECIMAL的返回类型为DECIMAL,其他为DOUBLE | AVG 窗口函数返回输入表达式值的平均值,忽略 NULL 值。 |
| COUNT() | BIGINT | COUNT 窗口函数计算输入行数。 COUNT(*) 计算目标表中的所有行,包括Null值;COUNT(expression) 计算特定列或表达式中具有非 NULL 值的行数。 |
| MAX() | 与传入参数类型一致 | MAX窗口函数返回表达式在所有输入值中的最大值,忽略 NULL 值。 |
| MIN() | 与传入参数类型一致 | MIN窗口函数返回表达式在所有输入值中的最小值,忽略 NULL 值。 |
| SUM() | 针对传参类型为DECIMAL的,返回类型一致;除此之外的浮点型为DOUBLE;传参类型为整数类型的,返回类型为BIGINT | SUM窗口函数返回所有输入值的表达式总和,忽略 NULL 值。 |
执行sum()聚合
select emp_name, emp_mgr, dealer_id, sales,
sum(sales) over () as sample1,
sum(sales) over (partition by dealer_id) as sample2,
sum(sales) over (partition by dealer_id ORDER BY stat_date) as sample3,
sum(sales) over (partition by dealer_id ORDER BY stat_date rows between unbounded preceding and current row) as sample4,
sum(sales) over (partition by dealer_id ORDER BY stat_date rows between 1 PRECEDING and CURRENT ROW) as sample5,
sum(sales) over (partition by dealer_id ORDER BY stat_date rows between 1 PRECEDING AND 1 FOLLOWING) as sample6,
sum(sales) over (partition by dealer_id ORDER BY stat_date rows between current row and unbounded following) as sample7
from q1_sales;
执行count()聚合
select emp_name, emp_mgr, dealer_id, sales,
count(sales) over () as sample1,
count(sales) over (partition by dealer_id) as sample2,
count(sales) over (partition by dealer_id ORDER BY stat_date) as sample3,
count(sales) over (partition by dealer_id ORDER BY stat_date rows between unbounded preceding and current row) as sample4,
count(sales) over (partition by dealer_id ORDER BY stat_date rows between 1 preceding and current row) as sample5,
count(sales) over (partition by dealer_id ORDER BY stat_date rows between 1 preceding and 1 following) as sample6,
count(sales) over (partition by dealer_id ORDER BY stat_date rows between current row and unbounded following) as sample7
from q1_sales;
执行avg()聚合
select emp_name, emp_mgr, dealer_id, sales,
avg(sales) over () as sample1,
avg(sales) over (partition by dealer_id) as sample2,
avg(sales) over (partition by dealer_id ORDER BY stat_date) as sample3,
avg(sales) over (partition by dealer_id ORDER BY stat_date rows between unbounded preceding and current row) as sample4,
avg(sales) over (partition by dealer_id ORDER BY stat_date rows between 1 preceding and current row) as sample5,
avg(sales) over (partition by dealer_id ORDER BY stat_date rows between 1 preceding and 1 following) as sample6,
avg(sales) over (partition by dealer_id ORDER BY stat_date rows between current row and unbounded following) as sample7
from q1_sales;
执行max()聚合
select emp_name, emp_mgr, dealer_id, sales,
max(sales) over () as sample1,
max(sales) over (partition by dealer_id) as sample2,
max(sales) over (partition by dealer_id ORDER BY stat_date) as sample3,
max(sales) over (partition by dealer_id ORDER BY stat_date rows between unbounded preceding and current row) as sample4,
max(sales) over (partition by dealer_id ORDER BY stat_date rows between 1 preceding and current row) as sample5,
max(sales) over (partition by dealer_id ORDER BY stat_date rows between 1 preceding and 1 following) as sample6,
max(sales) over (partition by dealer_id ORDER BY stat_date rows between current row and unbounded following) as sample7
from q1_sales;
执行min()聚合
select emp_name, emp_mgr, dealer_id, sales,
min(sales) over () as sample1,
min(sales) over (partition by dealer_id) as sample2,
min(sales) over (partition by dealer_id ORDER BY stat_date) as sample3,
min(sales) over (partition by dealer_id ORDER BY stat_date rows between unbounded preceding and current row) as sample4,
min(sales) over (partition by dealer_id ORDER BY stat_date rows between 1 preceding and current row) as sample5,
min(sales) over (partition by dealer_id ORDER BY stat_date rows between 1 preceding and 1 following) as sample6,
min(sales) over (partition by dealer_id ORDER BY stat_date rows between current row and unbounded following) as sample7
from q1_sales;
3. 执行窗口数据排名计算
Hive支持的窗口排名函数如下表所示:
| 窗口函数 | 返回类型 | 函数描述 |
|---|---|---|
| ROW_NUMBER() | BIGINT | 根据具体的分组和排序,为每行数据生成一个起始值等于1的唯一序列数。 |
| RANK() | BIGINT | 对组中的数据进行排名,如果名次相同,则排名也相同,但是下一个名次的排名序号会出现不连续。 |
| DENSE_RANK() | BIGINT | dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。当出现名次相同时,则排名序号也相同。而下一个排名的序号与上一个排名序号是连续的。 |
| PERCENT_RANK() | DOUBLE | 计算给定行的百分比排名。可以用来计算超过了百分之多少的人;排名计算公式为:(当前行的rank值-1)/(分组内的总行数-1)。 |
| CUME_DIST() | DOUBLE | 计算某个窗口或分区中某个值的累积分布。假定升序排序,则使用以下公式确定累积分布:小于等于当前值x的行数 / 窗口或partition分区内的总行数。其中,x 等于 order by 子句中指定的列的当前行中的值。 |
| NTILE() | INT | 已排序的行划分为大小尽可能相等的指定数量的排名的组,并返回给定行所在的组的排名。如果切片不均匀,默认增加第一个切片的分布,不支持ROWS BETWEEN。 |
执行窗口排名计算示例。
select *,
ROW_NUMBER() over(partition by dealer_id order by sales desc) rk01,
RANK() over(partition by dealer_id order by sales desc) rk02,
DENSE_RANK() over(partition by dealer_id order by sales desc) rk03,
PERCENT_RANK() over(partition by dealer_id order by sales desc) rk04
from q1_sales;
执行窗口累积分布。
select *,
CUME_DIST() over(partition by dealer_id order by sales ) rk05,
CUME_DIST() over(partition by dealer_id order by sales desc) rk06
from q1_sales;
执行窗口分桶操作
select *,
NTILE(2) over(partition by dealer_id order by sales ) rk07,
NTILE(3) over(partition by dealer_id order by sales ) rk08,
NTILE(4) over(partition by dealer_id order by sales ) rk09
from q1_sales;
下面代码使用窗口排名函数分组排名,对经销商的销售进行排名。
select *, row_number() over(partition by dealer_id order by sales desc) rk from q1_sales;
下面代码使用窗口排名函数取分组取第一名(分组Top 1)。
select * from (
select *,row_number() over(partition by emp_mgr order by stat_date desc) rk
from q1_sales
) tmp where rk = 1;
4. 执行窗口跨行取值计算
Hive支持的窗口跨行取值函数如下表所示:
| 窗口函数 | 函数描述 |
|---|---|
| LAG() | 与lead相反,用于统计窗口内往上第n行值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL。 |
| LEAD() | 用于统计窗口内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL。 |
| FIRST_VALUE() | 取分组内排序后,截止到当前行,第一个值。 |
| LAST_VALUE() | 取分组内排序后,截止到当前行,最后一个值。 |
注: last_value默认的窗口是 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,表示当前行永远是最后一个值。
执行以下代码,找出每个经销售最低销售额并添加到每一行:
select emp_name, dealer_id, sales,
first_value(sales) over (partition by dealer_id order by sales) as dealer_low
from q1_sales;
执行以下代码,找出2013年每个经销售最高销售额并添加到每一行:
select emp_name, dealer_id, sales, `year`,
last_value(sales) over (partition by emp_name order by `year` row between unbounded preceding and unbounded following) as last_sale from emp_sales
where `year` = 2013;
在下面这个应用示例中,我们使用窗口跨行取值函数实现环比计算。
什么是环比?与上月数据对比称”环比”。
环比增长率计算公式:(当月值-上月值)/上月值x100%
首先准备数据。
-- 创建表 create table saleorder( order_id int, order_time date, order_num int ); -- 插入测试数据 insert into saleorder values (1, '2020-04-20', 420), (2, '2020-04-04', 800), (3, '2020-03-28', 500), (4, '2020-03-13', 100), (5, '2020-02-27', 300), (6, '2020-01-07', 450), (7, '2020-04-07', 800), (8, '2020-03-15', 1200), (9, '2020-02-17', 200), (10, '2020-02-07', 600), (11, '2020-01-13', 300);
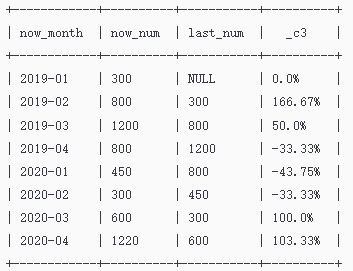
下面是环比增长率的计算:
select now_month, now_num, last_num,
concat( nvl ( round( ( now_num - last_num ) / last_num * 100, 2 ), 0 ), "%" )
from(
-- 2、查询上月销量
select now_month, now_num,
lag( t1.now_num, 1 ) over (order by t1.now_month ) as last_num
from (
-- 1、按月统计销量
select
substr(order_time, 1, 7) as now_month,
sum(order_num) as now_num
from saleorder
group by
substr(order_time, 1, 7)
) t1
) t2;
执行以上代码,最后计算出的结果如下表所示: