案例:亚马逊产品联购分析
本节通过一个案例,演示使用GraphFrame分析亚马逊产品2003年6月1日联购网络。本案例所使用的数据集由爬取亚马逊网站收集。它是基于亚马逊网站的“购买了该商品的顾客同时也购买了”功能。如果产品i经常与产品j共同购买,则图中包含从i到j的有向边。
数据集统计如下图所示。

首先导入依赖包,代码如下:
import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ import org.apache.spark.sql.Row import org.graphframes._ import spark.implicits._
加载联购数据,先把文件中的注释过滤掉,然后创建边DataFrame,再从边DataFrame中找出所有的顶点,创建顶点DataFrame。最后,由顶点DataFrame和边DataFrame创建图模型,代码如下:
// 1) 构造GraphFrame
// 加载数据到RDD
val filePath = "/data/amazon/Amazon0601.txt"
val edgesRDDRow = spark.sparkContext.textFile(filePath)
// 这是个坑:一定要对数据过滤,把注释过滤掉
val edgesRDD = edgesRDDRow.filter(line => !line.startsWith("#"))
// schema
val schemaString = "src dst"
val fields = schemaString
.split(" ")
.map(fieldName => StructField(fieldName, StringType, nullable = false))
val edgesSchema = new StructType(fields)
// 边DataFrame和顶点DataFrame
val rowRDD = edgesRDD
.map(_.split("\t"))
.map(attr => Row(attr(0).trim, attr(1).trim))
val edgesDF = spark.createDataFrame(rowRDD, edgesSchema)
// 从边RDD中计算出顶点RDD
val srcVerticesDF = edgesDF.select(col("src")).distinct()
val destVerticesDF = edgesDF.select(col("dst")).distinct()
val verticesDF = srcVerticesDF.union(destVerticesDF).distinct.select(col("src").alias("id"))
println("边的数量:" + edgesDF.count())
println("顶点的数量:" + verticesDF.count())
// 构造图模型
val g = GraphFrame(verticesDF, edgesDF)
1. 基本图查询和操作
接下来,介绍图结构上的简单的图查询和操作,包括顶点、边以及顶点入度和出度的显示,代码如下:
// 2)基本的图查询操作
// 顶点
g.vertices.show(5)
// 边
g.edges.show(5)
// 入度
g.inDegrees.show(5)
// 出度
g.outDegrees.show(5)
// 对边和顶点及其属性应用过滤器
g.edges.filter("src == 2").count()
g.edges.filter("src == 2").show()
g.edges.filter("dst == 2").show()
g.inDegrees.filter("inDegree >= 10").show()
// 对入度和出度使用groupBy和sort操作
g.inDegrees.groupBy("inDegree").count().sort(desc("inDegree")).show(5)
g.outDegrees.groupBy("outDegree").count().sort(desc("outDegree")).show(5)
2. 联购商品分析
Motifs可用于产品联购图中,根据表示产品的图的结构属性及其属性和它们之间的关系洞察用户行为。这些信息可用于推荐和/或广告引擎。
例如,指定motif模式表示一个用例,其中购买了产品(a)的客户还购买了另外两个产品(b)和(c),如下图所示。
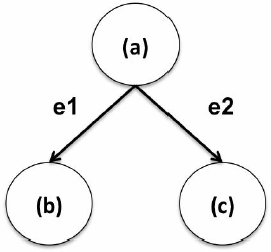
在下面这个简单查询中,搜索一系列产品,其中对产品a的购买也意味着对产品b的购买,反之亦然。这里的find操作将搜索由两个方向的边连接的顶点对。代码如下:
// 定义motif
val motifs = g.find("(a)-[e]->(b); (b)-[e2]->(a)")
motifs.show(5)
执行上面的代码,输出内容如下:
+--------+----------------+--------+----------------+ | a| e| b| e2| +--------+----------------+--------+----------------+ | [85609]| [85609, 100018]|[100018]| [100018, 85609]| | [86839]| [86839, 100042]|[100042]| [100042, 86839]| | [55528]| [55528, 100087]|[100087]| [100087, 55528]| |[178970]|[178970, 100124]|[100124]|[100124, 178970]| |[100124]|[100124, 100125]|[100125]|[100125, 100124]| +--------+----------------+--------+----------------+
还可以对结果应用过滤器。例如,在下面的过滤器中将顶点b的id值指定为2,这会找出所有与id为2的商品一齐被购买的其他商品,代码如下:
motifs.filter("b.id == 2").show()
执行上面的代码,输出内容如下:
+---+------+---+------+ | a| e| b| e2| +---+------+---+------+ |[3]|[3, 2]|[2]|[2, 3]| |[0]|[0, 2]|[2]|[2, 0]| |[1]|[1, 2]|[2]|[2, 1]| +---+------+---+------+
下面这种模式通常代表了这样一种情况:当顾客购买一种产品(a)时,她也会购买(b)和(c)其中之一,或都购买,如下图所示。
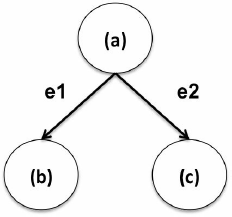
在该模式中,指定相同的顶点a是边e1和边e2的公共源,代码如下:
// 定义motif
val motifs3 = g.find("(a)-[e1]->(b); (a)-[e2]->(c)").filter("(b != c)")
motifs3.show(5)
执行以上代码,输出内容如下:
+--------+----------------+--------+----------------+--------+ | a| e1| b| e2| c| +--------+----------------+--------+----------------+--------+ |[109254]| [109254, 8742]| [8742]|[109254, 100010]|[100010]| |[109254]| [109254, 8741]| [8741]|[109254, 100010]|[100010]| |[109254]| [109254, 59782]| [59782]|[109254, 100010]|[100010]| |[109254]|[109254, 115349]|[115349]|[109254, 100010]|[100010]| |[109254]| [109254, 53996]| [53996]|[109254, 100010]|[100010]| +--------+----------------+--------+----------------+--------+
由于边列包含冗余信息,当不需要顶点或边时,可以省略它们的名称。例如,在模式(a)-[]->(b)中,[]表示顶点a和b之间的任意边。结果中没有用于边的列。同样,(a)-[e]->()表示顶点a的向外边,但不指定目标顶点。指定模式的代码如下:
val motifs3 = g.find("(a)-[]->(b); (a)-[]->(c)").filter("(b != c)")
motifs3.show(10)
println(motifs3.count())
执行以上代码,输出内容如下:
+--------+--------+--------+ | a| b| c| +--------+--------+--------+ |[109254]| [8742]|[100010]| |[109254]| [8741]|[100010]| |[109254]| [59782]|[100010]| |[109254]|[115349]|[100010]| |[109254]| [53996]|[100010]| |[109254]|[109257]|[100010]| |[109254]| [62046]|[100010]| |[109254]| [94411]|[100010]| |[109254]|[115348]|[100010]| |[117041]| [73722]|[100010]| +--------+--------+--------+ only showing top 10 rows 28196586
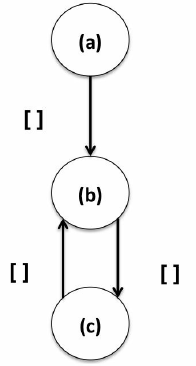
下面这种模式通常代表的情况是有一个往复a和b之间的关系(一个强连通分量表明这两种产品有相似之处),如下图所示。
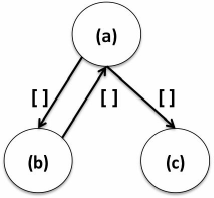
指定这个motif模式,代码如下:
val motifs3 = g
.find("(a)-[]->(b); (a)-[]->(c); (b)-[]->(a)")
.filter("(b != c)")
motifs3.show(10)
println(motifs3.count())
执行以上代码,输出结果如下:
+-------+--------+--------+ | a| b| c| +-------+--------+--------+ |[85609]|[100018]| [85611]| |[85609]|[100018]| [85610]| |[85609]|[100018]| [85752]| |[85609]|[100018]| [28286]| |[85609]|[100018]| [93910]| |[85609]|[100018]| [85753]| |[85609]|[100018]| [60945]| |[85609]|[100018]| [47246]| |[85609]|[100018]| [85614]| |[86839]|[100042]|[100040]| +-------+--------+--------+ only showing top 20 rows
下面这种模式代表了这样一种情况:当客户购买了不相关的产品(a和c)时,他们也会购买b。这是一个趋同的motif,例如,企业可以使用这些信息,将这些产品囤积在一起,如下图所示。
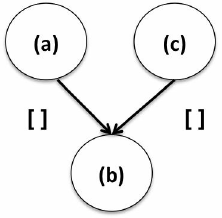
指定这个motif模式,代码如下:
val motifs3 = g.find("(a)-[]->(b); (c)-[]->(b)").filter("(a != c)")
motifs3.show(10)
println(motifs3.count())
执行以上代码,输出结果如下:
+--------+------+--------+ | a| b| c| +--------+------+--------+ |[365079]|[8742]|[100010]| |[241393]|[8742]|[100010]| | [33284]|[8742]|[100010]| |[198072]|[8742]|[100010]| |[203728]|[8742]|[100010]| |[109254]|[8742]|[100010]| |[256286]|[8742]|[100010]| | [45415]|[8742]|[100010]| |[372540]|[8742]|[100010]| | [96588]|[8742]|[100010]| +--------+------+--------+ only showing top 10 rows
在下面的模式中,指定了从a到b以及从b到c的边,还有一条从c到b的边。这种模式通常表示当客户购买产品(a)时,她也可能购买(b),然后继续购买(c)。这可以表示对所购买的物品有一定的优先次序。此外,mitif中的强连通组件表明(b)和(c)之间的密切关系,如下图所示。
指定这个motif模式,代码如下:
val motifs3 = g.find("(a)-[]->(b); (b)-[]->(c); (c)-[]->(b)")
motifs3.show(5)
println(motifs3.count())
执行以上代码,输出结果如下:
+--------+-------+--------+ | a| b| c| +--------+-------+--------+ |[188454]|[85609]|[100018]| | [85611]|[85609]|[100018]| | [98017]|[85609]|[100018]| |[142029]|[85609]|[100018]| | [64516]|[85609]|[100018]| | [85610]|[85609]|[100018]| |[106584]|[85609]|[100018]| |[261049]|[85609]|[100018]| |[331868]|[85609]|[100018]| | [98015]|[85609]|[100018]| +--------+-------+--------+ only showing top 10 rows
在下面这个模式中,指定了一个4节点的motif。该模式表示客户购买(b)的可能性较高的情况,如下图所示。
注意: 4节点motifs示例非常消耗资源,需要超过100gb的磁盘空间和14gb的RAM。另外,可以参考下一节来创建一个更小的子图来运行这个示例。
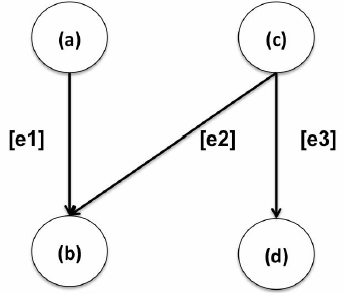
指定这个motif模式,代码如下:
// 确保磁盘空间>100 GB 并且 RAM >=14 GB
val motifs4 = g
.find("(a)-[e1]->(b); (c)-[e2]->(b); (c)-[e3]->(d)")
.filter("(a != c) AND (d != b) AND (d != a)")
motifs4.show(5)
motifs4.count()
3. 处理子图
基于motif查找和DataFrame过滤器的组合,GraphFrames提供了一种强大的方式来选择子图。例如,选择一个基于顶点和边过滤器的子图,代码如下:
// 选择子图
val v2 = g.vertices.filter("id < 10")
val e2 = g.edges.filter("src < 10")
val g2 = GraphFrame(v2, e2)
g2.edges.groupBy("src").count().show()
执行以上代码,输出结果如下:
+---+-----+ |src|count| +---+-----+ | 7| 10| | 3| 10| | 8| 10| | 0| 10| | 5| 10| | 6| 10| | 9| 10| | 1| 10| | 4| 10| | 2| 10| +---+-----+
然后基于子图进行查找和过滤,代码如下:
val paths = g.find("(a)-[e]->(b)").filter("e.src < e.dst")
paths.select("e.*").show(10)
执行以上代码,输出结果如下:
+------+------+ | src| dst| +------+------+ |100008|100010| |100226|100227| |100225|100227| |100224|100227| |100223|100227| |100262|100263| |100551|100553| |100552|100553| | 10095| 10096| |100963|100964| +------+------+ only showing top 10 rows
4. 应用图算法进行分析
首先,计算每个顶点的强连通分量(strongly connected component,SCC),并返回一个图,其中每个顶点都分配给包含该顶点的SCC。在SCC中显示节点数,代码如下:
// 设置检查点
spark.sparkContext.setCheckpointDir("hdfs://master:8020/cp")
// 强连通分量
val result = g.stronglyConnectedComponents.maxIter(10).run()
result.select("id", "component")
.groupBy("component")
.count()
.sort(col("count").desc)
.show(10)
接下来,计算通过每个顶点的三角形的数量,代码如下:
val results = g.triangleCount.run()
results.select("id", "count").show(10)
执行结果如下:
+------+-----+ | id|count| +------+-----+ |100010| 73| |100140| 15| |100227| 332| |100263| 9| |100320| 8| |100553| 41| |100704| 3| |100735| 13| |100768| 37| | 10096| 58| +------+-----+ only showing top 10 rows
在下面的示例中,应用PageRank算法来确定产品的重要性。潜在的假设是,更受欢迎的产品很可能从其他产品节点接收到更多的链接,代码如下:
val results = g.pageRank.resetProbability(0.15).tol(0.01).run()
val prank = results.vertices.sort(desc("pagerank"))
prank.show(10)
在下一个示例中,使用标签传播算法(Label Propagation algorithm)来查找图中产品的社区,代码如下:
val results = g.labelPropagation.maxIter(10).run()
results.select("id", "label").show(10)
results.select("id", "label")
.groupBy("label")
.count()
.sort(desc("count"))
.show(10)
下面使用最短路径算法来寻找图中两个顶点之间的路径,从而使其组成边的数量最小化,代码如下:
val results = g.shortestPaths.landmarks(Seq("1110", "352")).run()
results.select("id", "distances").take(5).foreach(println)