安装Apache Flume
Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume简介
Flume主要由3个重要的组件构成:
- Source:完成对日志数据的收集,分成transtion 和 event 打入到channel之中。
- Channel:主要提供一个队列的功能,对source提供中的数据进行简单的缓存。
- Sink:取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
Flume结构如下图所示:
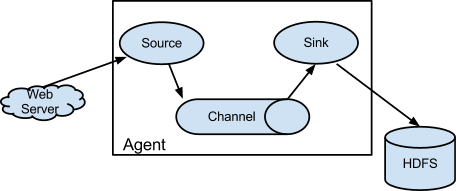
Flume逻辑上分为三层,分别是:agent,collector,storage。如下图所示:
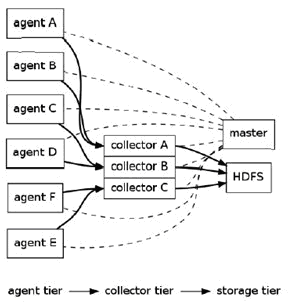
各层功能如下:
- agent层:用于采集数据。agent是flume中产生数据流的地方,同时,agent会将产生的数据流传输到collector。
- collector层:作用是将多个agent的数据汇总后,加载到storage中。
- storage层:存储系统,可以是一个普通文件,也可以是HDFS、HIVE、HBase、Kafka等。
安装Flume
请首先从Flume的官网上下载安装包。这里下载了apache-flume-1.9.0-bin.tar.gz,并将安装包上传到Linux系统中。
1)切换到安装包所在目录,执行如下的解压命令:
$ tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /home/hduser/bigdata
上面将apache-flume-1.9.0-bin.tar.gz解压到了/home/hduser/bigdata目录下。然后重命名文件夹,以简化引用。
$ cd /home/hduser/bigdata/ $ mv apache-flume-1.9.0-bin flume-1.9.0
2)现在编辑/etc/profile文件(或.bashrc文件)以更新Apache Flume的环境变量,以便可以从任何目录访问它。
$ nano /etc/profile
在打开的文件中,添加如下几行内容:
export FLUME_HOME=/home/hduser/bigdata/flume-1.9.0 export FLUME_CONF_DIR=$FLUME_HOME/conf export PATH=$PATH:$FLUME_HOME/bin
然后按CTRL + O保存修改,按CTRL + X退出nano编辑器,并执行以下命令使环境变量生效:
$ source /etc/profile
3)修改 flume-env.sh 配置文件。默认没有flume-env.sh,我们需要复制flume-env.sh.template并去掉后缀.template,命令如下:
$ cd /home/hduser/bigdata/flume-1.9.0/conf $ cp ./flume-env.sh.template ./flume-env.sh $ nano ./flume-env.sh
打开flume-env.sh文件以后,在文件的最后增加下面这行内容,用于设置JAVA_HOME变量:
export JAVA_HOME=/opt/java/jdk1.8.0_281
注意:这里请修改为你自己的JDK安装目录。
然后按CTRL + O保存修改,按CTRL + X退出nano编辑器
4)使用下面的命令来验证Flume的安装。
$ flume-ng version
如果安装成功,则应该出现Flume的版本信息,类似下面这样的内容:
Flume 1.9.0 Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git Revision: d4fcab4f501d41597bc616921329a4339f73585e Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018 From source with checksum 35db629a3bda49d23e9b3690c80737f9
恭喜!Apache Flume已经安装成功了!
