电信通话语音详单存储设计与实现
本节课,我们通过一个电信通话语音详单存储设计与实现的案例,学习和掌握以下内容:
- 项目背景
- 业务数据存储需求分析
- 数据模型设计,包括:
- 表结构设计
- rowkey设计
- 应用接口开发和测试程序开发
- 基于Phoenix SQL实现
项目背景
随着电信行业4G/5G 技术的普及以及移动互联网应用的不断发展,特别是手机、Pad、电脑等各种智能终端的广泛使用,每人每时每刻都在产生海量的数据。其中,数据记录了使用移动网络的时间、访问地址、位置信息和通信记录等。对于电信运营商来说,一方面,可以对这些数据进行分析,如分析网络瓶颈,开展网络优化等,为用户提供更好的服务;另一方面,可以为用户提供流量提醒、流量详单等实时查询,避免因为操作不规范、恶意软件等导致的流量过度消费,提高用户体验感知。因此,运营商需要构建一个适用于PB 级甚至EB 级大数据的查询处理平台,以提供更好的网络服务及用户体验。
通话语音详单记录的数据本身是个高价值的数据,它是目前为止可能是用户在移动互联网行为上的一个最基础、最原始的数据,这个数据如何进行高效的分析和挖掘。这么大的数据量,如何来进行低成本的存储,都是当时面临的问题。
面对PB 级、EB 级海量数据的实时查询, 现有技术方案主要采用传统关系型数据仓库。为了支撑更大的数据量、更高的查询速度,主要是通过分布式技术架构部署、增加硬件资源、采用高性能硬件设备等方式进行。其缺点如下。
- 数据入库效率差、并发能力差。使用关系型数据仓库的集群数量有限,并不能很好地扩展,而且大部分集群使用传统SAN 存储,存储的总I/O 吞吐量有限,难以满足每天数十TB 的数据处理要求,同时也无法应对将来更大数据量的处理需求。
- 数据统计查询效率低。传统的架构主要依赖于高端设备的I/O 能力及并发能力,但对于信令详单数据百亿级的数据量,传统集中式的架构查询统计效率无法满足要求。
- 系统扩展能力差。由于受限于系统软件架构,关系型数据仓库集群的节点数有限, 并行扩展能力不强,无法适用大数据的倍数增长。
- 软硬件成本高。由于采用商用软件,硬件一般采用高端硬件设备以提高系统性能及吞吐量,软硬件成本和维护费用非常高。因此,传统关系型数据仓库主要解决TB 级的数据分析应用,无法支撑语音详单PB 级、EB 级的大数据应用需求。
为了更有效地利用数据,发掘商业价值,提高网络质量,快速有效处理用户投诉,需要构建一种适用于PB 级、EB 级的语音详单实时查询及分析的平台。其中首先要做的,就是设计语音详单数据存储系统。
利用Hadoop和HBase可以帮助我们解决这些问题。Hadoop+HBase采用开源的方式,构架了普通的PC服务器之上,抛弃了高端的存储,也可以保证高可靠性,适合数据快速的写入,以及有快速检索的方式。
业务数据存储需求分析
随着信息技术和经济社会的发展,我国成为全球最大的互联网、电子商务和智能终端市场,移动通信用户数达到 13 亿。电信业务数据中的详单查询是电信企业的一项主要应用。
计费详单数据分为语音详单及数据详单,包含用户当月的每一次语音通话及数据上网业务记录。其中语音详单主要记录用户的语音通话信息,包含用户ID、时间、通话时长、LAC、CI等信息;数据详单主要记录用户的上网信息,包含用户ID、时间、上行流量、下行流量、LAC、CI等信息。计费详单数据可以用来分析用户的业务行为、业务量,结合用户消费信息间接估算出收入情况。
某电信项目中采用HBase来存储用户终端明细数据,供前台页面即时查询。业务数据包括语音话单业务数据和上网业务数据,业务数据表中最小超过4 亿条记录/天,最大超过100 亿条记录/天,数据总量超过20 TB/天,数据保存一个月,总存储量达到PB 级别,7×24 h 不间断进行数据处理,HBase 集群机器均衡配置各40 台机器。
数据模型设计
HBase 是构建于HDFS 上可伸缩、分布式、列式动态模式的Hadoop 数据库。HBase 的模型结构在Schema 声明的时候创建,与传统关系型数据库的差异在于没有固定的结构化。
表结构设计
HBase 表的基本结构由rowkey、column family(列族)、column(列族中的列)、time stamp(时间戳)组成。每个数据单元格是由{rowkey、column、version}组成,每组单元格内容是不可分割的字节数组。在构建HBase 这种列式key-value 模型时,尽量少创建列族,以避免数据空缺差异很大,导致不均匀分布,影响查询性能。
数据建模需要根据业务需求和集群硬件资源情况来设计,一般可以分为以下两种。
- 高表:多行少列(可以存储大对象,也可以存储小对象),方便管理,耗费的资源多, 有利于做MapReduce 分析。
- 宽表:少行多列(如客户关系中某用户办理的业务),有利于提升查询性能,但MapReduce 分析处理相对较繁琐。
高表结构的模型设计如下图所示。
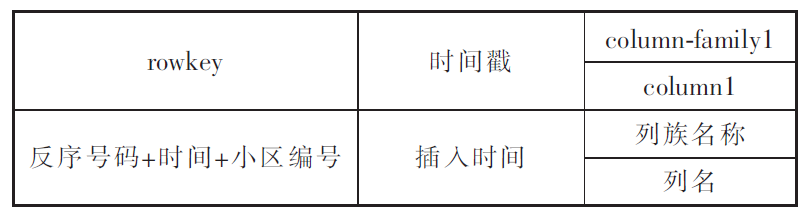
宽表结构的模型设计如下图所示。

rowkey设计
HBase中rowkey是主键,其设计也至关重要,入库数据会更根据rowkey进行排序, 数据分布式按照rowkey范围来划分。为了将数据均匀分布到每台机器上,防止热region导致数据堆积在某一台或者多台机器上,rowkey中的号码组成部分需要反序,这样数据分布均匀程度会高很多,同时随机插入的数据会被分配到对应region 中。
HBase 的表数据按照rowkey 规则分布, 分布规则如下图所示。
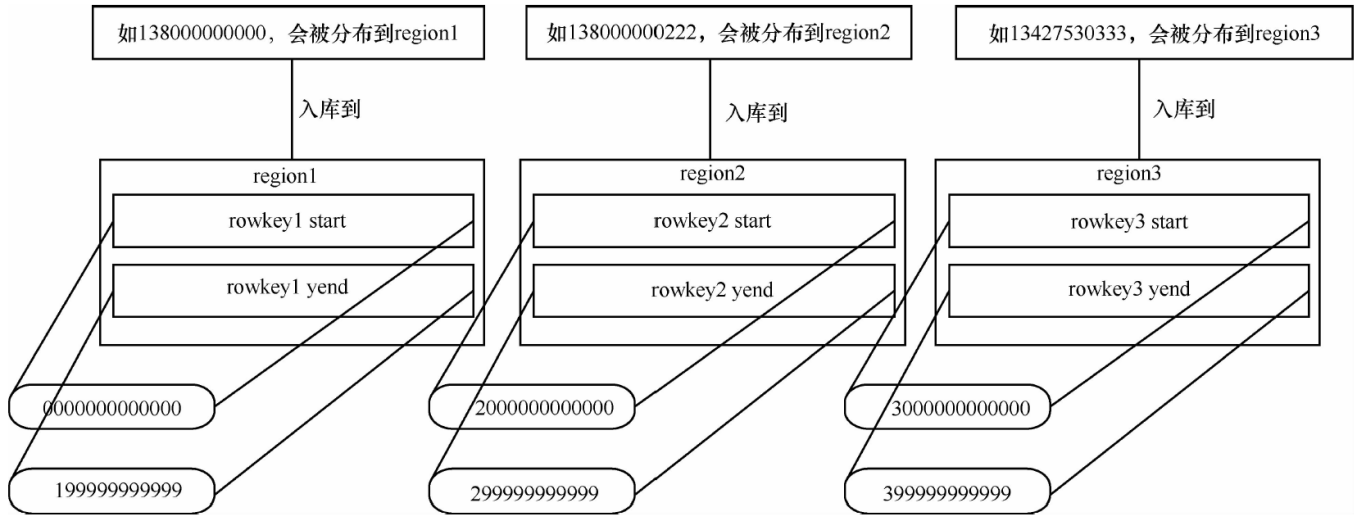
HBase 的表由region 组成,region 默认均匀分布在不同机器上。region 二个重要的属性: StartKey 与EndKey,表示这个region 维护的rowkey 范围, 当要读/写数据时, 如果rowkey 落在某个start-end key 范围内, 那么就会定位到目标region 并且读/写到相关的数据。
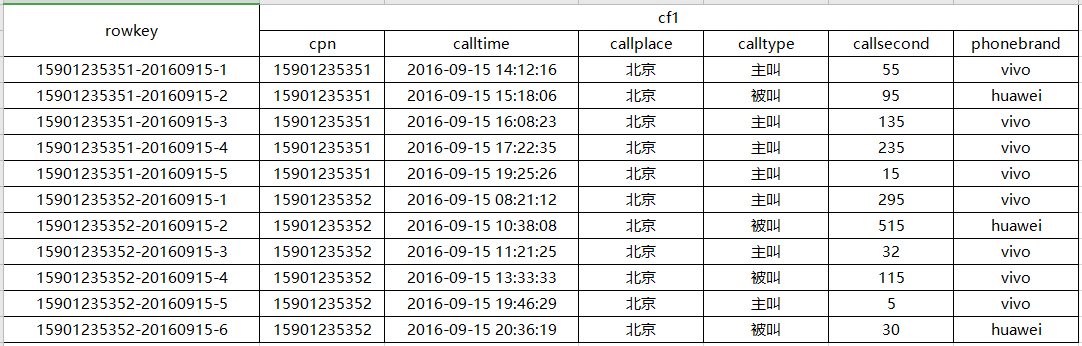
对于rowkey 的设计,还需要结合数据实际查询场景,通过rowkey能满足主要的查询需求。在本案例中,用户登录后,需要根据用户的手机号行来查询通话记录信息,所以行健里边应该包含手机号,这样同一个人的通话记录会存储在一个连续的物理位置。仅仅这样还不够,考虑到客户查询通话记录往往是按照时间去检索,所以行健里边也要包含日期信息,这样相同手机号、相同日期的数据会存储在一个连续的物理位置,相同手机号、前一天的的数据和后一天的数据会存储在相邻的位置。最后,为了保持行健的唯一性,根据时间先后顺序,可以为同一个手机号在同一天产生的语音详单数据生成一个自增的整数值。
根据上面的思想,行键的构造:手机号-呼叫日期-自增序号。最终的行健数据信息如下。
应用接口开发和测试程序开发
应用接口包括如下几个类。
1)首先是HBase表的元数据信息:
public class HBaseTablesMeta {
// hbase数据库连接信息
public static final String HBASE_ROOTDIR = "hdfs://localhost:8020/hbase";
public static final String HBASE_ZOOKEEPER_QUORUM = "localhost"; // .META.
public static final String HBASE_ZOOKEEPER_PROPERTY_CLIENTPORT = "2181";
// callrecord1表
public static final String TABLE_CALL_RECORD = "callrecord"; // 表名
public static final String INFO_CF1 = "baseinfo"; // 列族 versions=5
public static final String INFO_CF2 = "otherinfo"; // 列族 versions=3
}
2)用来构造行键的工具类:
import java.util.HashMap;
import java.util.Map;
// 用来构造行键的工具类
public class RowKeyConverter {
private static final int STATION_ID_LENGTH = 2;
private static Map<String,Long> phoneId = new HashMap<>();
public static String makeRowKey(String phoneNumber, String calltime) {
Long id = phoneId.get(phoneNumber);
if(null == id) {
id = 1L;
}else {
id += 1;
}
phoneId.put(phoneNumber, id); // 写回
String date = calltime.split(" ")[0].replace("-", "");
String rowkey = phoneNumber + "-" + date + "-" + id;
return rowkey;
}
}
3)HBase工具类实现:
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
// 访问HBase数据库的工具类
public class HBaseUtil {
private static Configuration config;
private static Connection connection;
private static Admin admin; // DML操作:创建和管理数据表
// 和数据库建立连接
public static void init(String rootdir, String zkQuorum, String clientPort) {
// 获得配置对象
config = HBaseConfiguration.create();
config.set("hbase.rootdir", rootdir);
// 设置Zookeeper,直接设置IP地址
config.set("hbase.zookeeper.quorum", zkQuorum);
config.set("hbase.zookeeper.property.clientPort", clientPort);
// 创建和数据库的连接
try {
System.out.println("正在和数据库建立连接...");
connection = ConnectionFactory.createConnection(config);
admin = connection.getAdmin();
System.out.println("已和数据库建立连接");
} catch (IOException e) {
System.out.println("无法和数据库建立连接");
e.printStackTrace();
}
}
// 关闭连接
public static void close() {
try {
if (null != admin) {
admin.close();
}
if (null != connection) {
connection.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
// 创建表:表名,列族数组
/**
*
* @param tableName
* 表名
* @param columnFamiles
* 列族数组
* @throws IOException
* 抛出的异常
*/
public static void createTable(String tableName, String[] columnFamiles) throws IOException {
// hbase没有数据类型,都是字符串
TableName tbName = TableName.valueOf(tableName);
// 先判断表是否存在
if (admin.tableExists(tbName)) {
System.out.println("表已经存在");
return;
}
// 如果表还不存在,则创建它
HTableDescriptor htd = new HTableDescriptor(tbName);
// 将所有的列族依次加入到表中
for (String family : columnFamiles) {
HColumnDescriptor hcd = new HColumnDescriptor(family);
hcd.setMaxVersions(5); // 设置最大版本数
htd.addFamily(hcd);
}
// 最后,通过admin来创建表
admin.createTable(htd);
}
// 添加数据:表名,行键, 列族,列限定符,值
/**
*
* @param tableName
* 表名
* @param rowkey
* 行键
* @param family
* 列族
* @param qualifier
* 列限定符
* @param value
* 单元格的值
* @throws IOException
* 抛出的异常
*/
public static void add(String tableName, String rowkey, String family, String qualifier, String value)
throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
try {
// 封装一条信息:Put
Put put = new Put(rowkey.getBytes());
// Put put = new Put(Bytes.toBytes(rowkey));
// 向put中填充指定的列和值
put.addColumn(family.getBytes(), qualifier.getBytes(), value.getBytes());
table.put(put); // 将put添加到表中
} finally {
table.close();
}
}
// 重载的add方法,put里面有多个列限定符
/**
*
* @param tableName
* @param rowkey
* @param family
* @param columnAndValue
* key是qualifier,value是cell value
* @throws IOException
*/
public static void add(String tableName, String rowkey, String family, Map<String, String> columnAndValue)
throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
try {
// 封装一条信息:Put
Put put = new Put(Bytes.toBytes(rowkey));
for (Map.Entry<String, String> kv : columnAndValue.entrySet()) {
// 向put中填充指定的列和值
put.addColumn(family.getBytes(), Bytes.toBytes(kv.getKey()), Bytes.toBytes(kv.getValue()));
}
table.put(put); // 将put添加到表中
} finally {
table.close();
}
}
// 查询指定行(键)和列族对应的记录
public static Result query(String tableName, String rowkey, String family) throws IOException {
// 获得对表的引用
Table table = connection.getTable(TableName.valueOf(tableName));
Result result = null;
try {
// 封装一条信息:Get
Get get = new Get(Bytes.toBytes(rowkey));
get.addFamily(Bytes.toBytes(family));
result = table.get(get);
} finally {
table.close();
}
return result;
}
// 查询指定单元格中的数据
public static String query(String tableName, String rowkey, String family, String qualifier)
throws IOException {
// 获得对表的引用
Table table = connection.getTable(TableName.valueOf(tableName));
// 封装一条信息:Get
Get get = new Get(rowkey.getBytes());
get.addFamily(family.getBytes());
Result result = table.get(get);
byte[] byteValues = result.getValue(family.getBytes(), qualifier.getBytes());
String value = new String(byteValues);
return value;
}
// 查找多个单元格中的数据
public static List<String> query(String tableName, String[] rowkeys, String family, String qualifier)
throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
List<Get> listOfGets = new ArrayList<>();
for (String rowkey : rowkeys) {
listOfGets.add(new Get(Bytes.toBytes(rowkey)));
}
Result[] records = table.get(listOfGets);
List<String> values = new ArrayList<>();
for (Result r : records) {
byte[] b = r.getValue(Bytes.toBytes(family), Bytes.toBytes(qualifier));
values.add(new String(b));
}
return values;
}
// 查找多个单元格中的数据
public static List<String> query(String tableName, String[] rowkeys, String family, String[] qualifiers)
throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
List<Get> listOfGets = new ArrayList<>();
for (String rowkey : rowkeys) {
listOfGets.add(new Get(Bytes.toBytes(rowkey)));
}
Result[] records = table.get(listOfGets);
List<String> values = new ArrayList<>();
StringBuilder builder;
for (Result r : records) {
builder = new StringBuilder();
for (String qualifier : qualifiers) {
byte[] b = r.getValue(Bytes.toBytes(family), Bytes.toBytes(qualifier));
builder.append(new String(b));
builder.append(", ");
}
values.add(builder.toString());
}
return values;
}
// 扫描全表
public static List<String> scan(String tableName)
throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
List<String> values = new ArrayList<>();
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
try {
Iterator<Result> results = scanner.iterator();
while (results.hasNext()){
Result r = results.next();
String rowkey = Bytes.toString(r.getRow());
Cell calltime = r.getColumnLatestCell( Bytes.toBytes("baseinfo"), Bytes.toBytes("calltime"));
Cell callplace = r.getColumnLatestCell(Bytes.toBytes("baseinfo"),
Bytes.toBytes("callplace"));
Cell calltype = r.getColumnLatestCell( Bytes.toBytes("baseinfo"),
Bytes.toBytes("calltype"));
Cell callsecond = r.getColumnLatestCell(Bytes.toBytes("baseinfo"),
Bytes.toBytes("callsecond"));
Cell phonebrand = r.getColumnLatestCell(Bytes.toBytes("otherinfo"),
Bytes.toBytes("phonebrand"));
String callTime = Bytes.toString(CellUtil.cloneValue(calltime));
String callPlace = Bytes.toString(CellUtil.cloneValue(callplace));
String callType = Bytes.toString(CellUtil.cloneValue(calltype));
String callSecond = Bytes.toString(CellUtil.cloneValue(callsecond));
String phoneBrand = Bytes.toString(CellUtil.cloneValue(phonebrand));
String line = rowkey + "," + callTime + "," + callPlace + "," + callType + "," +
callSecond + "," + phoneBrand;
values.add(line);
}
} finally {
scanner.close();
}
return values;
}
}
4)主驱动程序:
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class CallDriver {
public static void main(String[] args) throws IOException {
// 不变的代码逻辑和可变的数据表信息分开存储
String hbaseRootDir = HBaseTablesMeta.HBASE_ROOTDIR;
String zookeeperQuorum = HBaseTablesMeta.HBASE_ZOOKEEPER_QUORUM;
String zookeeperClientPort = HBaseTablesMeta.HBASE_ZOOKEEPER_PROPERTY_CLIENTPORT;
// 连接数据库
HBaseUtil.init(hbaseRootDir,zookeeperQuorum,zookeeperClientPort);
// 创建表
String[] columnFamiles = {HBaseTablesMeta.INFO_CF1,HBaseTablesMeta.INFO_CF2};
try {
HBaseUtil.createTable(HBaseTablesMeta.TABLE_CALL_RECORD, columnFamiles);
} catch (IOException e) {
System.out.println("创建数据表时出错!");
e.printStackTrace();
}
String[] callRecords = {
"15901235351,2016-09-15 14:12:16,北京,主叫,55,vivo",
"15901235357,2016-09-15 14:13:16,北京,主叫,95,huawei",
"15901235351,2016-09-15 14:23:16,北京,被叫,135,vivo",
"15901235357,2016-09-16 09:13:16,北京,主叫,235,huawei",
"15901235351,2016-09-16 10:23:16,北京,被叫,15,vivo",
"15901235357,2016-09-16 11:13:16,北京,主叫,295,huawei",
"15901235357,2016-09-16 12:23:16,北京,被叫,515,vivo",
"15901235349,2016-09-16 16:23:16,北京,被叫,595,vivo"
};
// 向表中插入数据
// 表名
String tableName = HBaseTablesMeta.TABLE_CALL_RECORD;
Map<String, String> columnAndValue = null;
System.out.println("开始写数据...");
for(String record : callRecords) {
String[] items = record.split(",");
// 生成行键
String rowkey = RowKeyConverter.makeRowKey(items[0], items[1]);
String family1 = "baseinfo";
columnAndValue = new HashMap<>();
columnAndValue.put("calltime", items[1]);
columnAndValue.put("callplace", items[2]);
columnAndValue.put("calltype", items[3]);
columnAndValue.put("callsecond", items[4]);
HBaseUtil.add(tableName, rowkey, family1, columnAndValue);
String family2 = "otherinfo";
String qualifier = "phonebrand";
String value = items[5];
// 将一条通话记录写入(put)到hbase的数据表中
HBaseUtil.add(tableName, rowkey, family2, qualifier, value);
}
System.out.println("开始扫描数据...");
// 查询浏览表
List<String> results = HBaseUtil.scan(tableName);
for(String line : results) {
System.out.println(line);
}
}
}
基于Phoenix SQL实现
上面的功能,如果不使用代码,而是通过Phoenix使用SQL实现的话,如下所示:
-- 创建电信语音详单表
-- 行键的构造:手机号-呼叫日期-自增序号
-- 两个列族:baseinfo, otherinfo
-- "15901235351,2016-09-15 14:12:16,北京,主叫,55,vivo",
-- "15901235357,2016-09-15 14:13:16,北京,主叫,95,huawei",
-- "15901235351,2016-09-15 14:23:16,北京,被叫,135,vivo",
-- "15901235357,2016-09-16 09:13:16,北京,主叫,235,huawei",
-- "15901235351,2016-09-16 10:23:16,北京,被叫,15,vivo",
-- "15901235357,2016-09-16 11:13:16,北京,主叫,295,huawei",
-- "15901235357,2016-09-16 12:23:16,北京,被叫,515,vivo",
-- "15901235349,2016-09-16 16:23:16,北京,被叫,595,vivo"
CREATE TABLE IF NOT EXISTS callrecord(
rowkey varchar NOT NULL PRIMARY KEY,
baseinfo.cpn varchar,
baseinfo.calltime varchar,
baseinfo.callplace varchar,
baseinfo.calltype varchar,
baseinfo.callsecond integer,
otherinfo.phonebrand varchar
);
-- 删除表
-- DROP TABLE callrecord;
-- 插入数据
UPSERT INTO callrecord values('15901235351-20160915-1','15901235351','2016-09-15 14:12:16','北京','主叫',55,'vivo');
UPSERT INTO callrecord values('15901235357-20160915-1','15901235357','2016-09-15 14:13:16','北京','主叫',95,'huawei');
UPSERT INTO callrecord values('15901235351-20160915-2','15901235351','2016-09-15 14:23:16','北京','被叫',135,'vivo');
UPSERT INTO callrecord values('15901235357-20160916-2','15901235357','2016-09-16 09:13:16','北京','主叫',235,'huawei');
UPSERT INTO callrecord values('15901235351-20160916-3','15901235351','2016-09-16 10:23:16','北京','被叫',15,'vivo');
UPSERT INTO callrecord values('15901235357-20160916-3','15901235357','2016-09-16 11:13:16','北京','主叫',295,'huawei');
UPSERT INTO callrecord values('15901235357-20160916-4','15901235357','2016-09-16 12:23:16','北京','被叫',515,'vivo');
UPSERT INTO callrecord values('15901235349-20160916-1','15901235349','2016-09-16 16:23:16','北京','被叫',595,'vivo');
查询
SELECT * FROM callrecord;
查询结果如下:

模糊查询
查询所有15901235351的通话信息:
SELECT * FROM callrecord WHERE rowkey LIKE '15901235351%';
查询结果如下:

查询2016年9月15号的所有呼叫:
SELECT * FROM callrecord WHERE rowkey LIKE '%20160915%';
查询结果如下:

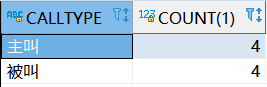
统计主叫和被叫的次数:
SELECT calltype,count(1) FROM callrecord GROUP BY CALLTYPE;
查询结果如下:
结束语
随着移动互联网的发展,信息量及用户量将继续不断增长,传统运营商必将面临在大数据处理方面更多的压力。基于对电信语音数据特点及查询统计需求的分析,通过创建数据模型、设计高效的rowkey 及二级索引,使用合理的数据压缩方法等技术建立的详单查询平台,可以有效地解决海量语音数据详单等大数据的实时业务需求,解决传统技术架构的瓶颈。