发布日期:2021-11-02
MapReduce连接运算
在实际中,有很多场景都要求将多个数据集连接起来。
连接(Join)是关系运算,可以用于合并关系(relation)。对于数据库中的表连接操作,可能已经广为人知了。在MapReduce中,连接可以用于合并两个或多个数据集。
最常用的两个连接类型是内连接(inner join)和外连接(outer join)。 如下图所示,内连接比较两个关系中所有的元组,判断是否满足连接条件,然后生成一个满足连接条件的结果集。 与内连接相反的是,外连接并不需要两个关系的元组都满足连接条件。 在连接条件不满足的时候,外连接可以将其中一方的数据保留在结果集中。
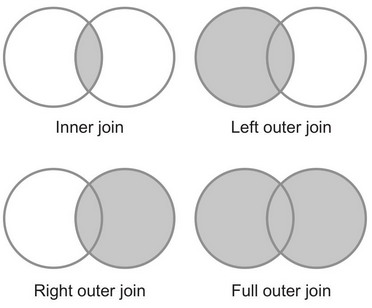
为了实现内连接和外连接,MapReduce中有两种连接策略,如下所示。
- map端连接。使用场景:待连接的数据集中有一个数据集足够小到可以完全放在缓存中。 在这种类型中,连接是在map函数实际使用数据之前执行的。 每个map的输入必须以分区的形式并按顺序排列。 此外,必须有相同数量的分区,并且必须按连接key进行排序。 也就是说,要连接的数据集已经按相同的键进行排序,并且拥有相同数量的分区。
- reduce端连接。使用场景:连接两个或多个大型数据集。 当连接由reducer执行时,它被称为reduce-side联接。 在此连接中,没有必要使用结构化形式(或分区形式)的数据集。
连接选择策略
MapReduce连接策略可被总结以下三点:
- 1) 如果其中有一个数据集小到足够放入到一个mapper的内存,则map only复制连接最有效。
- 2) 如果两个数据集都很大,其中一个数据集可通过预过滤(与其它数据集数据不匹配的)元素而大大减少体积,则semi-join(半连接)最合适。
- 3) 如果不能对数据进行预处理,并且数据体积太大而不能被缓存—这意味着我们不得不在reducer端执行join连接—需要使用重分区连接(repartition join)。
课程章节 返回课程首页
-
Ch01 Hadoop概述及环境搭建
-
Ch02 HDFS分布式文件系统
-
Ch03 MapReduce计算框架
- Hadoop MapReduce架构
- MapReduce基础案例01-单词计数v1
- MapReduce基础案例02-单词计数v2
- MapReduce基础案例03-单词计数v3
- MapReduce基础案例04-统计年最高温度
- MapReduce基础案例05-订单数据统计
- MapReduce基础案例06-计算平均成绩
- MapReduce基础案例07-大数据去重
- MapReduce基础案例08-大数据排序
- MapReduce基础案例09-自定义分区器
- MapReduce基础案例10-倒排索引_1
- MapReduce基础案例11-倒排索引_2
- MapReduce基础案例12-酒店数据清洗
- MapReduce基础案例13-计数器
-
Ch04 开发复杂的MapReduce应用程序
- 选择合适的Hadoop数据类型
- 使用Hadoop ArrayWritable数据类型
- 使用Hadoop MapWritable数据类型
- 自定义的Hadoop Writable数据类型
- 自定义的Hadoop Key数据类型
- 从Mapper发出不同value类型的数据
- 使用KeyValueTextInputFormat
- 实现自定义的InputFormat
- 使用Hadoop OutputFormat输出格式
- 自定义Hadoop OutputFormat输出格式
- 一个MapReduce计算写入多个输出
- 一个MapReduce计算写入多个输出_2
- MapReduce案例-实现Top N算法
- MapReduce案例-二次排序算法_示例1
- MapReduce案例-二次排序算法_示例2
- MapReduce案例-分布式缓存共享数据
- MapReduce案例-使用Hadoop计数器
- MapReduce案例-写入数据库表
- MapReduce案例-读取数据库表
-
Ch05 MapReduce实现表连接